2026 年 4 月、Findy が主催したオンラインイベント「Harness Engineering 入門 〜 AI エージェントを制御するアプローチ〜」が開催された。r.kagaya 氏の登壇「エージェントの開発環境を内製して気づいた『これもハーネス』」は参加者から「レベル高すぎた」と評されるほど反響を呼んだ。本記事では、r.kagaya 氏が公開した SpeakerDeck 資料「ハーネスエンジニアリングにどう向き合うか 〜ルールファイルを超えて開発プロセスを設計する〜」をもとに、ルールファイルを超えたハーネスエンジニアリングの考え方を整理する。
イベント概要
【Harness Engineering 入門】AIエージェントを制御するアプローチ(connpass #388471)は、AI エージェントによる開発が広まる中でハーネス設計がどのような意味を持つかを掘り下げるイベント。対象は AI エージェントを積極的に使っているエンジニア、チーム開発に AI を取り込もうとしているエンジニア層だ。
複数の登壇の中で r.kagaya 氏のセッションは、自社でエージェントの開発環境を内製する過程で見えてきた「これもハーネスだ」という気づきを軸に、ルールファイル設定で終わらないハーネスエンジニアリングの本質を語った。
ルールファイルから始まるハーネスエンジニアリング
多くのエンジニアがハーネスエンジニアリングを始める入り口は CLAUDE.md などのルールファイル だ。「こういうコードを書いてほしい」「このコマンドは使わないで」といった制約を自然言語で記述し、AI の振る舞いをコントロールする。
| |
この段階では「うまく動くルールを育てる」フェーズであり、試行錯誤でルールを追加・削除していく。しかし、ここで止まってしまうと 本当の意味でのハーネスエンジニアリング には到達できない。
ルールファイルの限界
ルールファイルだけに依存したアプローチには構造的な限界がある。
| 課題 | 内容 |
|---|---|
| 変更の影響が不透明 | あるルールを変えたとき、どの程度・どの方向に結果が変わるか測定できない |
| 劣化の検知が困難 | モデルのアップデートや使い方の変化でルールの有効性が静かに落ちる |
| 再現性の欠如 | 同じルールで試しても毎回違う結果が出る場合の原因特定が難しい |
| スケールしない | チームが大きくなるほど「誰がどのルールを管理しているか」が曖昧になる |
ルールファイルを超えた視点:開発プロセスとして設計する
r.kagaya 氏が提示したのは、ハーネスエンジニアリングを「ルールを書く行為」ではなく 「開発プロセスを設計する行為」 として捉え直す考え方だ。
1. 実行履歴・思考履歴を資産にする
AI エージェントの実行ログ(tool_use の記録、thinking の内容)は単なるデバッグ情報ではなく、ハーネスを改善するための一次データ だ。どのルールが効いているか、どこで意図と外れているかは、ログを系統的に分析して初めてわかる。
2. 評価基準を先に定義する
「うまくいった」「失敗した」の判断を人間の直感だけに頼るのをやめ、評価基準(Evaluation Criteria) を明示的に定義する。これにより:
- ルール変更前後の A/B 比較が可能になる
- 回帰テストとして過去の失敗ケースを再チェックできる
- チーム全員が同じ基準で品質を判断できる
3. 評価と監視を継続的改善のエンジンにする
評価基準を定めたら、それを継続的に計測する監視の仕組みを整える。「評価 → 実行ログ収集 → 基準に照らした評価 → 改善」のサイクルこそがハーネスエンジニアリングの本質だ。
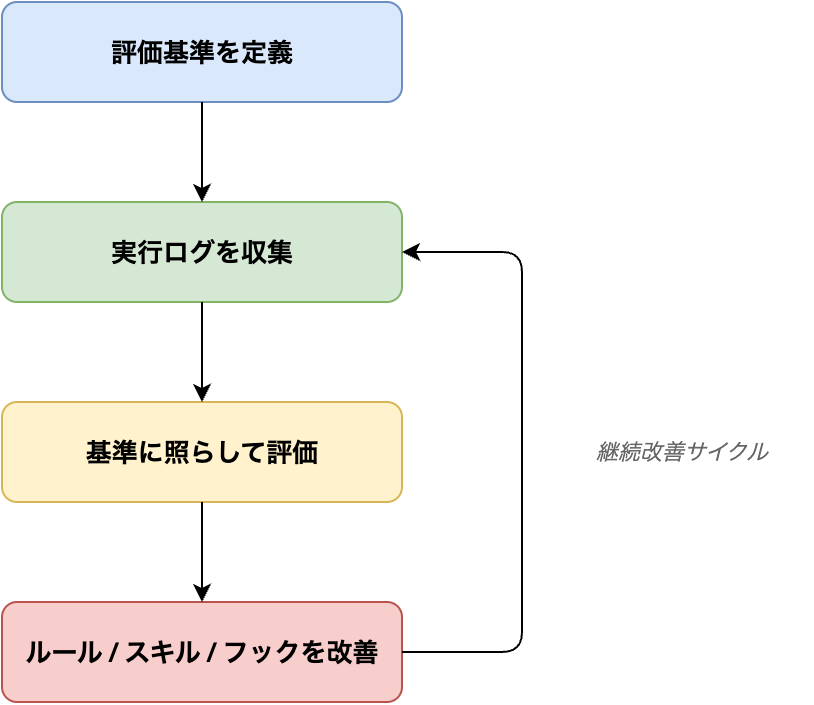
4. ソフトウェアエンジニアリングの規律を持ち込む
ハーネスはコードと同様に バージョン管理・テスト・CI/CD の対象として扱う。「先週のルールと今週のルール、どちらが良いか」を定量的に比較できる状態を作ることが、長期的な品質維持の鍵になる。
5. パイプライン設計とトリガー拡張
CLAUDE.md で書くのが難しい複雑なロジックは、Claude Agent SDK を使ったパイプライン化 へと昇華させる。入力の前処理、ツール呼び出しのバリデーション、出力の後処理を明示的なコードとして管理することで、ルールファイルだけでは表現できないフローを制御できる。
実践への入り口
r.kagaya 氏のメッセージを端的にまとめると「ハーネスエンジニアリングをソフトウェアエンジニアリングとして扱え」だ。以下のステップが出発点になる。
- まずログを取る — AI の実行過程を記録し、後から分析できる形にする
- 失敗ケースを定義する — 「これは失敗」という具体的なサンプルをリストアップする
- 評価スクリプトを書く — 定義した基準を自動でチェックするコードを用意する
- ルール変更を PR にする — CLAUDE.md の変更をコードと同様にレビューする
- 指標を可視化する — 品質指標をダッシュボードで継続観測する
まとめ
ルールファイルは「始まり」であって「終わり」ではない。AI エージェントを継続的に高品質に動かし続けるためには、評価・監視・改善のサイクルをソフトウェア工学の文脈に落とし込む必要がある。
SpeakerDeck で公開されている登壇資料も合わせて確認することをすすめる。