「現在の90%のAI Agentの記憶は偽物だ」——AI研究者 @AYi_AInotes がXでこう発言し、大きな反響を呼んでいる。
多くの開発者が同じ罠にはまっている。「会話履歴や決定ログをMarkdownファイルに溜め込めば長期記憶になる」という誤解だ。
この記事では、なぜMarkdownダンプが「記憶」ではないのか、4つの根本的欠陥と2026年時点で実用可能なグラフ×埋め込みベースの代替設計を解説する。
Markdownファイルへの履歴ダンプが崩壊するまで
@AYi_AInotes 自身の失敗談がわかりやすい。失敗は次の順序で進んだ。
- 全ての会話履歴・決定ログをMarkdownファイルに蓄積
- 「これで長期記憶が実現できた」と信じる
- 2週間で崩壊
崩壊の具体的な症状:
- 同一事実に3つの矛盾バージョンが存在する — 上書きも検証もなく書き足し続けた結果
- 先月の好みと昨日の重みが同等に扱われる — 時系列の概念がない
- 毎回全コンテキストを詰め込む — 遅延増大、コンテキスト汚染(クロストーク)が頻発
Markdownベース記憶の4つの根本的欠陥
1. 重複排除がない(No Deduplication)
同じ情報が何度も書き込まれ、どれが最新・正確かわからなくなる。矛盾する記述が増え続け、Agentが混乱する。
2. セマンティック検索ができない(No Semantic Retrieval)
キーワードマッチしか使えず、関連情報を文脈で引き出せない。「先月の判断」と「今月の判断」の関係性が見えない。
3. 時系列優先度がない(No Temporal Weighting)
古い情報と新しい情報が同等に扱われる。ユーザーの好みが変化しても、Agentは古い情報に引きずられる。
4. エンティティ間の関係を持てない(No Relationship Modeling)
「AとBは関係がある」「Cの前提はDである」という構造を表現できない。フラットなテキストでは知識の構造化が不可能。
PromptをRAMとして使うことの問題
Markdownダンプを人間の記憶に例えると:
- 脳に情報を定着させるのではなく、ノートに書いて毎回全文を読み返すようなもの
- ノートが増えるほど読み返す時間が増え、矛盾も増える
- これは記憶ではなく、外部ストレージへの都度参照だ
本物の記憶は:
- 関連情報を索引化して素早く引き出せる
- 同じ情報を重複して持たない(圧縮・統合)
- 時間の経過とともに重要度が変化する
- 事実間の関係性を持つ
Markdownダンプはこれを一切満たさない。PromptをRAMとして使っているだけだ。
本物の記憶 = グラフ + ベクトル埋め込み + トラバーサル
本物の記憶の設計原則は3つのコンポーネントで構成される:
グラフ(Graph)
知識をノードとエッジで構造化する。エンティティ(人、概念、出来事)をノードとして、その関係をエッジとして保存する。「AはBを好む」「CはDに依存する」という関係が明示的に管理できる。
埋め込み(Embeddings)
各ノードをベクトルに変換することで、意味的に近い情報を検索できる。「先週の決定」と「今週の状況」の意味的類似性を計算し、関連する記憶だけを取り出せる。
トラバーサル(Traversal)
グラフを辿ることで、直接リンクされていない関連情報も発見できる。「ユーザーの好みA → 関連する行動B → 影響を受けた決定C」という連鎖をたどれる。
Mem0・memsearch・memweave — AIエージェント記憶フレームワーク比較
| システム | アーキテクチャ | 特徴 |
|---|---|---|
| Mem0 | ベクトルストア + 知識グラフ | 約73%トークン削減(実測値)、91%レイテンシ改善(p95) |
| memsearch (Zilliz) | Markdown + Milvusシャドウインデックス | Markdownをソース、ベクトルDBをインデックスに分離 |
| memweave | Markdown + SQLite | インフラ不要、BM25 + ベクトル検索のハイブリッド |
| ハイブリッド検索 | BM25 + Vector + Graph | キーワード・セマンティック・関係の3ストリーム |
Mem0のグラフ強化バリアント「Mem0g」は、抽出フェーズでベクトルストアと並行して有向ラベル付き知識グラフを構築する。
2024年には実験段階だったグラフ記憶が、2026年には本番運用フェーズに入っている。Mem0の論文(arXiv:2504.19413)では実測で91%のp95レイテンシ改善が確認されている。
補足:「ベクトルDB + RAG」を出発点にするのは現実的か
ここまで読んで「では、ベクトルDBをバックエンドにRAGを組めば記憶は実装できるのか?」と考えるかもしれない。結論から言うと、出発点として現実的だが、それだけでは前述の4つの欠陥のうち1つしか解決できない。
純粋な Vector DB + RAG が解決すること・しないこと
| 欠陥 | 純 RAG で解決? |
|---|---|
| ① 重複排除 | ❌ チャンク単位で重複したまま埋め込まれる |
| ② セマンティック検索 | ✅ ここがRAGの本領 |
| ③ 時系列重み付け | ❌ メタデータ + リランキングを自前で実装する必要 |
| ④ 関係モデリング | ❌ 埋め込みは「意味的近さ」までで関係そのものは表現できない |
つまり「ベクトルDBを入れた = 記憶ができた」ではなく、RAGはあくまで検索層であって、その上に抽出・統合・時系列・グラフのレイヤーを積み上げて初めて「記憶」と呼べる。
2026年の現実的な選択肢(コスト順)
Tier 1: pgvector + 自前ロジック(MVP)
- PostgreSQL + pgvector で「ベクトルDB」を1つ減らす
- LLM で会話から fact を抽出 → 重複検出 → upsert
created_atカラム + 時間減衰スコアでリランキング- 小規模(〜1万エントリ)なら最も現実的。新規インフラ不要
Tier 2: Mem0 / Letta(旧 MemGPT)を採用
- 抽出・重複排除・更新ロジックがフレームワーク内で完結
- Mem0 は内部的に Vector Store + Knowledge Graph のハイブリッド
- 「自前で書きたくない」ならこれが本命。Mem0 のマネージド版もある
- 前述の 91% p95 レイテンシ改善はこちら
Tier 3: GraphRAG / Mem0g(関係性が効く領域)
- エンティティ間の関係が業務価値の中核(例: 法務・医療・サプライチェーン)
- LLM による知識グラフ構築コストが追加で発生
- オーバーキルになりがち。Tier 2 で頭打ちを感じてから移行で十分
Graph DB をどこに置くか — 単一 PostgreSQL か別 DB か
ここまでの Tier 1/2/3 を読んで「Tier 1 の entity_id カラムは、もしかして PostgreSQL に Graph DB 相当のテーブルも用意するという意味?」と感じた人もいるかもしれない。Tier 1 の段階では entity_id は将来のための採番だけで、関係性そのものはまだ保存していない。(田中)-[勤務]->(ACME) のようなエッジは、この時点では存在しない。
ただし、関係性が必要になった段階で「Graph をどこに置くか」には複数の選択肢があり、必ずしも Neo4j のような専用 DB を別途立てる必要はない。実は単一 PostgreSQL のまま Graph 機能を載せるパスが現実的に存在する。
選択肢 A: 素の PostgreSQL に nodes / edges テーブルを追加(Tier 1.5)
| |
Recursive CTE (WITH RECURSIVE) で graph traversal を SQL で書ける。小〜中規模(〜数百万エッジ)なら十分実用で、memory.entity_id = nodes.entity_id で Vector と Graph を JOIN できる。
選択肢 B: Apache AGE 拡張を入れる
PostgreSQL に Cypher クエリを実装する拡張。MATCH (a)-[r]->(b) のような Neo4j 風クエリが書け、単一 DB で本格的な Graph DB として運用できる。
選択肢 C: Neo4j など専用 Graph DB を別立て
数千万〜億エッジ、複雑なトラバーサルが必要なときの最終形。運用負荷は最大になる。
配置パターンの比較
| ステージ | 構成 | 用意するもの | 想定規模 |
|---|---|---|---|
| Tier 1(推奨スタート) | PostgreSQL + pgvector | memory テーブル 1 つ。Graph テーブルなし | 〜10万 fact |
| Tier 1.5(単一 DB に Graph 追加) | PostgreSQL + pgvector + nodes/edges | 同一 DB に Graph 相当テーブルを追加。Apache AGE もアリ | 〜数百万エッジ |
| Tier 2/3 | PostgreSQL(vector)+ Neo4j / Mem0 / GraphRAG | Graph を別 DB に分離 | 数千万〜億エッジ |
運用負荷を抑えたい中小規模では、「PostgreSQL 1 個で vector + graph + 通常データを全部持つ」(Tier 1.5) が現実的な落とし所になることが多い。バックアップ・トランザクション・接続管理が一元化でき、entity_id を共通キーにした JOIN で Vector と Graph を縫い合わせられる。
「Graph DB と聞いたら Neo4j」と短絡せず、まず単一 PostgreSQL でどこまで戦えるかを検討するのが、2026年の運用視点では最も賢い選択になる。
Vector と Graph はどう結合するのか
Tier 2/3 に進むと「Vector DB と Graph DB をどう繋ぐのか」という疑問が出てくる。ここでよくある誤解が「Vector の関連性を Graph で関連付ける」という捉え方だ。実際の設計はそうではなく、両者は別種の関連性を別々に持ち、共通の entity_id でブリッジする という構造になっている。
まず、2つの「関連性」が質的に違うことを押さえておきたい。
| Vector DB が表す関連性 | Graph DB が表す関連性 | |
|---|---|---|
| 種類 | 意味的類似度(fuzzy) | 明示的な関係(typed, explicit) |
| 例 | 「この文章はあの文章に似ている」 | 「田中は ACME 社に 勤務する」 |
| 検索 | コサイン距離 | エッジを辿る (traversal) |
| 強み | 曖昧なクエリでも引ける | 多段の論理関係を辿れる |
| 弱み | 「なぜ関連?」を説明できない | 事前に関係を抽出する必要 |
Vector の「意味的に近い」と Graph の「A が B を所有する」は質的に違う情報なので、片方をもう片方に変換することはできない。役割分担として理解する必要がある。
実際に Mem0g や GraphRAG が内部でやっているのは、次のような 「抽出 → 二重保存 → 二段検索」 のパターンだ。
[ユーザー発話]
↓ LLM 抽出
├──→ Graph DB: (田中)-[勤務]->(ACME) ← node に entity_id="tanaka_001"
└──→ Vector DB: 「田中はACMEで働いている」のベクトル ← metadata.entity_id="tanaka_001"
[検索時]
1. クエリをベクトル化 → Vector DB で類似テキストを発見 → entity_id="tanaka_001" を取得
2. その entity_id で Graph DB に飛ぶ → 田中の周辺ノード(同僚、所属部署、過去案件)を取得
3. Vector のヒットテキスト + Graph のサブグラフ を両方 LLM に渡す
つまり設計上の役割は次のように整理できる。
- ❌ Vector の出力を Graph に変換する、という方向ではない
- ✅ Vector で「入口」を見つけ、Graph で「周辺」を広げる(役割分担)
- ✅ 両者を 共通の entity_id(または fact_id)で縫い合わせる(ブリッジの実装)
実装ステップに落とすと以下のようになる。
- 抽出層で会話 → エンティティ + 関係 + 事実 に分解(LLM が担当)
- エンティティと事実に ID を採番
- Vector DB: 事実テキストを埋め込み、metadata に entity_id を持たせる
- Graph DB: エンティティをノード、関係をエッジとして保存
- 検索時: Vector で初期ヒット → entity_id 経由で Graph をトラバーサル
この構造を把握しておくと、Mem0 や GraphRAG が内部で何をしているかが見通せるようになり、自前実装に切り替える判断もしやすくなる。
LLM を Graph 構築のどこに使うか
「抽出 → 二重保存」の抽出フェーズで LLM を使うのは当然だが、LLM は単なる抽出器ではなく、Graph 構築パイプラインの 5 つのフェーズすべてに介入させるのが2026年のベストプラクティスだ。1回抽出して保存するだけだと、結局 Markdown ダンプと同じ「重複・矛盾」問題が graph 上で再発する。
LLM が介入する 5 フェーズ
| フェーズ | LLM の役割 | サボるとどうなる |
|---|---|---|
| ① 抽出 (Extract) | 文書から entity / relation / fact を抽出 | 関係漏れ、幻覚関係 |
| ② 正規化 (Canonicalize) | 表記揺れを統合(“田中” / “田中さん” / “Mr. Tanaka”) | 同一人物が別ノード化 |
| ③ 衝突解決 (Reconcile) | 既存 graph と矛盾する事実の処理 | 古い情報が残る |
| ④ 拡張 (Enrich) | 暗黙の関係・時制・否定の補完 | 構造が浅くなる |
| ⑤ 検証 (Validate) | 抽出結果のレビュー・品質スコア付け | 幻覚が graph に定着 |
推奨される 3 つの抽出パターン
パターン A: スキーマ駆動抽出(最も安定)
事前にオントロジー(許可するエンティティ型・関係型)を定義し、LLM の出力をそこに強制する。
| |
- 長所: 幻覚関係が混入しない、graph スキーマが安定
- 短所: 想定外の関係を取りこぼす
- 向き: HR・法務・医療などドメインが明確な領域
パターン B: Open Information Extraction(柔軟)
LLM に自由に triple (subject, predicate, object) を抽出させる。GraphRAG はこちら寄り。
入力: 「田中は2021年に ACME に入社し、現在は CTO を務める」
出力:
(田中, 入社, ACME) {at: 2021}
(田中, 役職, CTO) {as_of: 現在}
- 長所: スキーマ設計コスト不要、未知の関係も拾える
- 短所: 述語の表記揺れ(“勤務” / “所属” / “在籍”)が発生 → 後段で正規化必須
- 向き: ドメイン未確定、探索的な記憶構築
パターン C: エージェント駆動の漸進構築(最も賢い)
LLM エージェントが「既存 graph を検索 → 新規か既存か判定 → 必要なら新ノード追加 → 関係を張る」を会話単位で実行する。
Agent thought:
1. クエリ「田中」で graph 検索 → tanaka_001 (ACME 勤務) がヒット
2. 今回の発話「田中が転職した」と矛盾検出
3. 既存エッジ (tanaka_001)-[勤務]->(ACME) に終了日を付与
4. 新エッジ (tanaka_001)-[勤務]->(NewCo) を追加
- 長所: 衝突解決と漸進更新が同時に実現
- 短所: トークンコストが高い、レイテンシ大
- 向き: パーソナルアシスタントなど更新頻度の高い記憶
モデル選定の現実解
すべてを Opus でやるとコスト爆発するため、役割で切り分けるのが定石になっている。
| タスク | 推奨モデル | 理由 |
|---|---|---|
| 単純な triple 抽出 | Haiku 4.5 または Triplex | 大量バッチ、コスト最重視 |
| 正規化・dedup | Haiku 4.5 + 埋め込みクラスタリング | 多くは類似度で十分 |
| 衝突解決・暗黙関係抽出 | Sonnet 4.6 | 推論が必要、頻度は中程度 |
| エージェント駆動更新 | Sonnet 4.6 + tool use | tool use が安定 |
| 検証・サンプル監査 | Opus 4.7 | 少量・高品質 |
「Haiku でドラフト → Sonnet で衝突解決 → Opus で抜き打ち監査」という3段構えが、品質とコストのバランス点になる。
既存フレームワークの内部実装に学ぶ
ゼロから組まなくても、以下が同じ思想で実装済みだ。
| ツール | 採用パターン | 特徴 |
|---|---|---|
| Microsoft GraphRAG | パターン B + LLM 生成のコミュニティ要約 | クエリ時に LLM が要約を再ランキング |
| Mem0g | パターン C + LLM による fact 更新 | 既存 fact との矛盾を LLM が判定して update |
| Neo4j LLM Knowledge Graph Builder | パターン A/B 切替可能 | UI で確認しながら構築 |
| LlamaIndex KGIndex | パターン B | 抽出と検索が一体 |
| Triplex (SciPhi) | パターン B 専用の小型モデル | GPT-4 比 1/100 コスト |
落とし穴と対策
- 幻覚関係 — LLM が「ありそうな関係」を勝手に作る
- 対策: 抽出時に原文の引用 (provenance) を必ず metadata に保存し、後で監査可能にする
- エンティティ重複 — 同じ「田中」が
tanaka_001とtanaka_042に分裂- 対策: 抽出後、埋め込み近傍検索 → 閾値超えは LLM に「同一か?」を確認
- graph の発散 — 関係型が無限に増える
- 対策: 月次で LLM に「述語クラスタリング → 統合候補提案」をさせるメンテナンスバッチ
- 古い事実の残留 — 「田中は ACME 勤務」が元社員になっても残る
- 対策: すべての fact に
valid_from/valid_toのテンポラル情報を持たせ、エージェントが更新時に閉じる
- 対策: すべての fact に
最小実装テンプレート
「とりあえず動かす」なら以下が出発点になる。
| |
要点は、LLM を「ワンショット抽出器」ではなく「graph の編集権限を持つメンテナンス担当」として設計すること。これが Mem0g や GraphRAG が実用段階に入った最大の差分になっている。
推奨スタートライン
pgvector + LLM 抽出 + timestamp による時間減衰
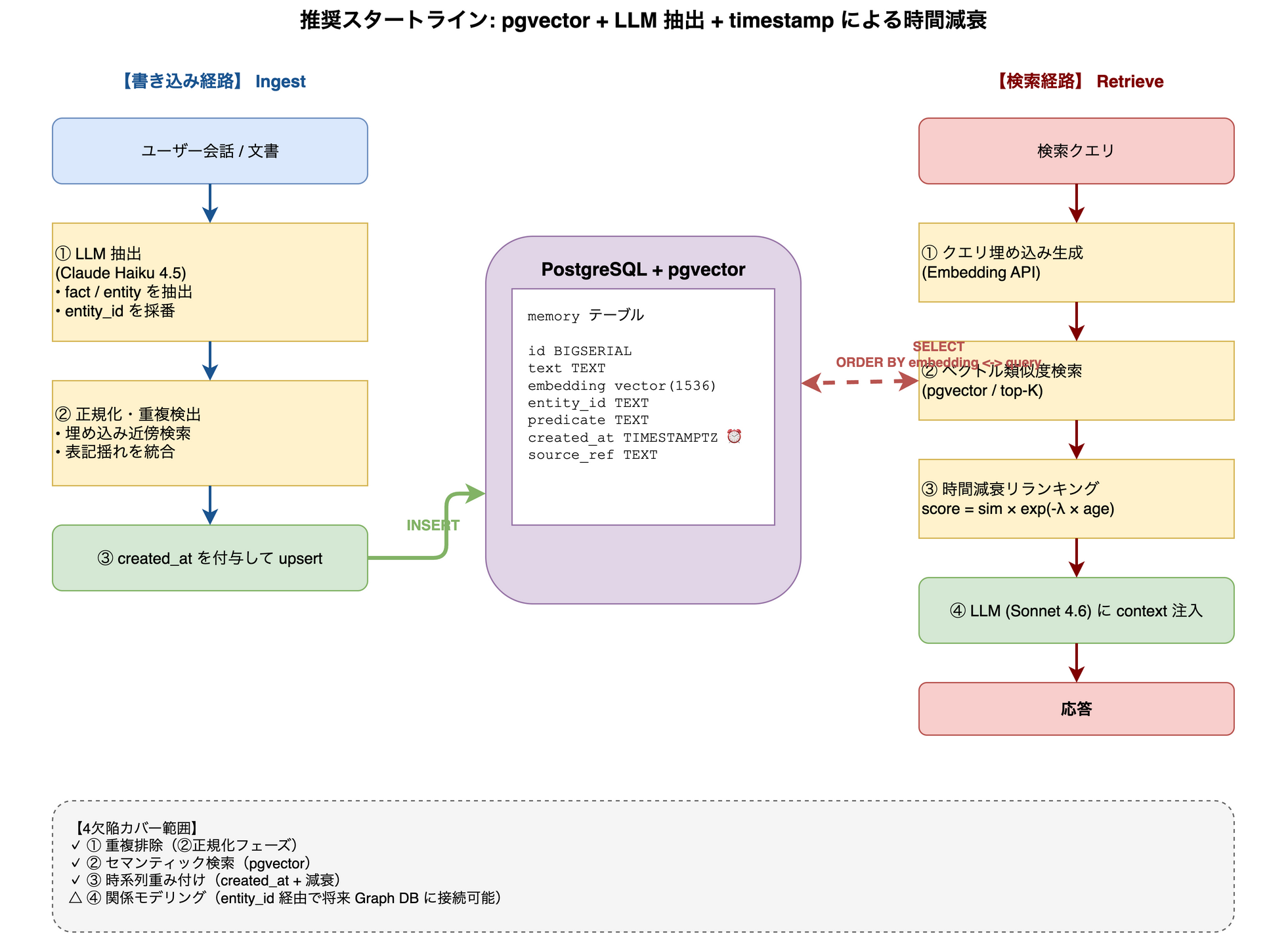
このアーキテクチャの要点は3つだ。
- ストレージは PostgreSQL 1 個に集約: pgvector で「ベクトル DB」を別途立てる必要がなく、運用負荷が最小
- LLM 抽出層を必ず挟む: 会話を生のまま入れず、Haiku 4.5 等で fact 単位に分解してから保存。これで重複排除(①)の足場ができる
created_atで時間減衰を持たせる: 検索時にscore = similarity × exp(-λ × age)でリランキング。古い情報の重みが自動的に下がる
これで4欠陥のうち②③に加え、抽出層を入れることで①も部分的にカバーできる。④(関係性)が本当に必要になった段階で、前述の entity_id ブリッジ構造を活かし、Tier 1.5(同じ PostgreSQL に nodes/edges テーブルを追加) か Mem0 / GraphRAG に移行するのが、2026年における ROI 最良の進め方だ。
「いきなり Knowledge Graph」は構築・メンテコストが高すぎて多くのプロジェクトが頓挫している。RAG は「すべての記憶システムが必ず満たすべき下限」、Graph は「関係性が本当に効く領域でだけ追加する上澄み」 と捉えるのが実態に合っている。多くのプロジェクトは下限だけで十分機能する。
まとめ
「AIに記憶を持たせる」というのは、単にファイルに書き込むことではない。
本物のAgent記憶システムには:
- グラフ構造によるエンティティと関係の管理
- ベクトル埋め込みによるセマンティック検索
- 時系列重み付けによる優先度管理
- 重複排除による整合性維持
が必要だ。2026年現在、Mem0やmemsearchなどのフレームワークでこれらの設計が実用段階に入っている。
Markdownファイルへの履歴ダンプから卒業し、構造化されたグラフ×埋め込みベースの記憶設計に移行する時期が来ている。