VibeVoice は、60 分の長尺 ASR(音声認識)と 90 分のマルチ話者 TTS(音声合成)をローカル無料で実現する Microsoft 製の OSS 音声 AI。本記事では特徴・モデル構成・TTS コード削除の経緯を解説する。
microsoft/VibeVoice は GitHub スター数 45,000 超(2026-04-29 時点)。ICLR 2026 に Oral 採択されたペーパーも公開されており、ASR・TTS の両領域で「フロンティア級」と呼べる性能を、軽量モデルで提供している。一方で、後述のとおり利用可能性については重要な注意点がある。
VibeVoice とは何か
VibeVoice は、TTS と ASR を統合した「音声 AI モデルファミリー」として Microsoft Research が公開している OSS。中核のイノベーションは、7.5 Hz という超低フレームレートで動作する連続音声トークナイザー(Acoustic + Semantic)を用いて、長尺音声の処理効率と忠実度を両立した点にある。
LLM(Qwen2.5 1.5B ベース)が文脈・対話の流れを理解し、Diffusion ヘッドで高品質な音響細部を生成する next-token diffusion フレームワークを採用している。
モデルラインナップ
| モデル | パラメータ | 用途 | 状態 |
|---|---|---|---|
| VibeVoice-ASR-7B | 7B | 60分対応の話者識別付き音声認識 | ✅ 利用可能 |
| VibeVoice-TTS-1.5B | 1.5B | 90分・最大4話者の長尺TTS | ⚠️ コード削除済み |
| VibeVoice-Realtime-0.5B | 0.5B | 約300ms の低遅延ストリーミングTTS | ✅ 利用可能 |
1. VibeVoice-ASR — 60分の長尺音声認識(文字起こし)
従来の ASR は音声を短いチャンクに分割するため、長尺になると話者識別や文脈の一貫性が失われやすい。VibeVoice-ASR は 64K トークン長で最大 60 分の連続音声を 1 パスで処理できる。
主な特徴:
- 構造化された出力: 「Who(誰が)/ When(いつ)/ What(何を)」の3要素を含むトランスクリプトを生成(ASR + ダイアライゼーション + タイムスタンプ)
- 50言語以上のマルチリンガル対応: ネイティブで多言語サポート
- ホットワード指定: ドメイン固有の専門用語・人名・背景情報をプロンプトとして与えて認識精度を向上
- vLLM による高速推論: 通常の Transformers 経由に加えて vLLM 推論にも対応
- Hugging Face Transformers 統合: 2026-03-06 のリリースで
transformersライブラリから直接利用可能に
オンラインの Playground で試せる。
2. VibeVoice-Realtime-0.5B — 300ms 起動のリアルタイム音声合成
リアルタイム音声生成向けの軽量モデル。
- パラメータサイズ 0.5B(デプロイメントしやすい)
- 初回発話までのレイテンシは約 300 ミリ秒
- ストリーミングテキスト入力に対応
- 約 10 分の長尺生成も可能
- 2025-12-16 のアップデートで、9言語(DE / FR / IT / JP / KR / NL / PL / PT / ES)の多言語ボイスと、英語の 11 種類のスタイルボイスを実験的に追加
Colab デモ で実際に動かせる。
3. VibeVoice-TTS-1.5B — 90分・4話者の長尺TTS(提供停止中)
ICLR 2026 に Oral 採択された目玉モデル。1パスで最大 90 分、最大 4 話者の対話音声を、話者一貫性を保ったまま生成できる。ただし、後述の事情により現状はコードが削除されている。
⚠️ VibeVoice-TTS のコードは削除されている
リポジトリの News セクションに、Microsoft からの以下の声明が掲載されている:
2025-09-05: VibeVoice is an open-source research framework intended to advance collaboration in the speech synthesis community. After release, we discovered instances where the tool was used in ways inconsistent with the stated intent. Since responsible use of AI is one of Microsoft’s guiding principles, we have removed the VibeVoice-TTS code from this repository.
つまり、2025-08-25 に公開された VibeVoice-TTS は、意図に反する使われ方(おそらくディープフェイク等の悪用)が確認されたため、Microsoft が同年 9 月にコードをリポジトリから削除している。README のモデル一覧でも VibeVoice-TTS-1.5B の Quick Try は “Disabled” と表示されている。
ペーパーや Hugging Face のウェイト情報は残っているが、「Microsoft 公式の TTS-1.5B をすぐに動かす」ことは現状できない。代替として:
- 長尺 TTS が欲しい場合: VibeVoice-Realtime-0.5B(10分まで)または他の OSS TTS を検討
- 研究目的: ペーパー(ICLR 2026 Oral)で技術詳細は公開されている
ライセンスと商用利用上の留意点
VibeVoice の README 末尾には「Risks and Limitations」セクションがあり、以下の警告が明記されている:
- ベースモデル(Qwen2.5 1.5b)由来のバイアス・誤りを継承する可能性がある
- ディープフェイクや偽情報生成への悪用リスク: 高品質な合成音声は、なりすまし・詐欺・偽情報拡散に悪用される懸念がある
- ユーザーは生成コンテンツの信頼性を確認し、誤解を招く形で使わない責任を負う
- AI 生成コンテンツの開示が推奨されている
実際に TTS コードが削除された前例があるため、配布形態が今後変わる可能性も念頭に置きたい。
iPad / iPhone を入力端末とする場合の典型構成
iPadOS / iOS には Python ランタイムも CUDA も無いため、端末側でモデルを動かすことは現実的ではない。代わりに、端末は録音・再生・UI に専念し、推論はサーバ側 GPU で行う構成が定番となる。
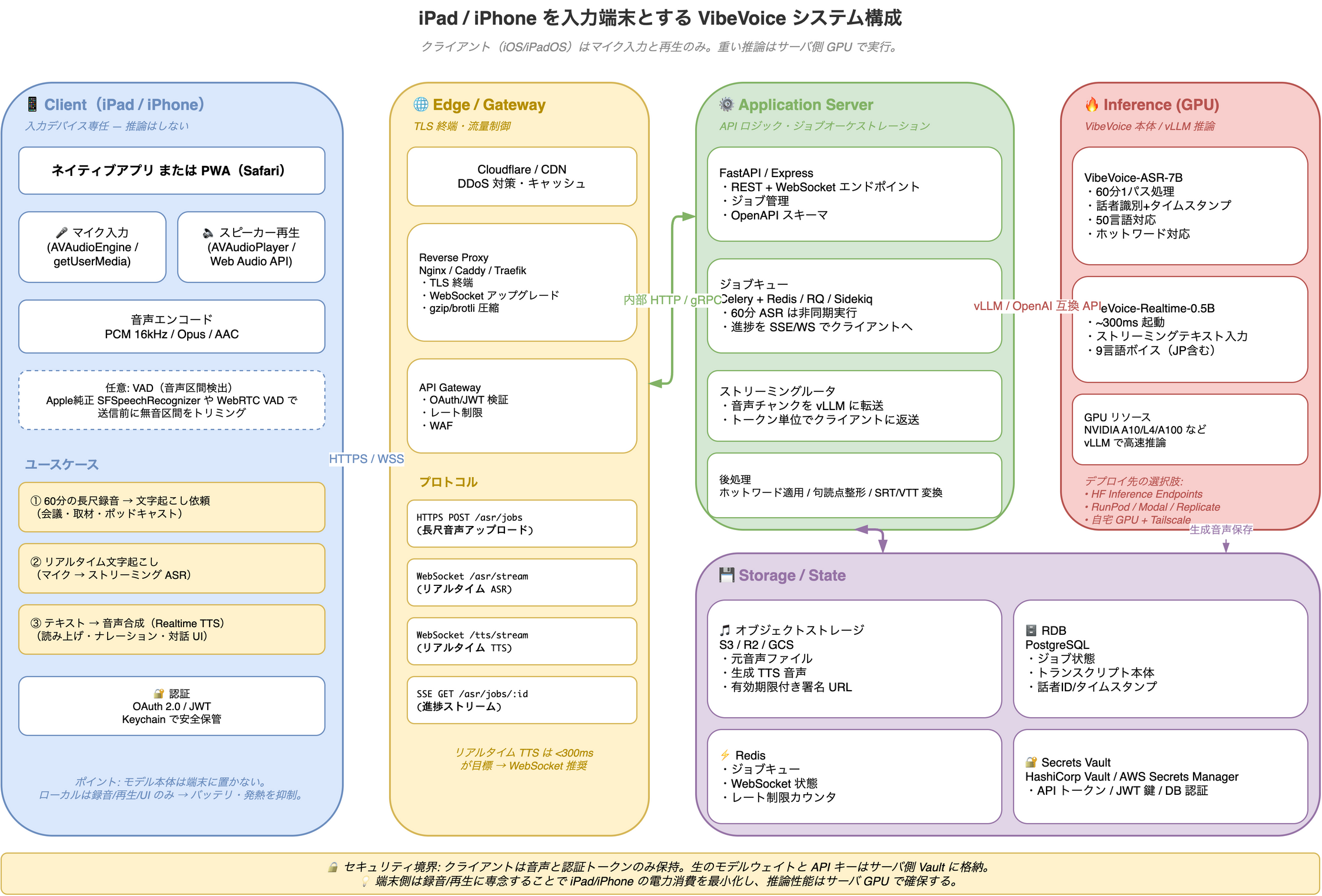
各層の役割
- 📱 Client(iPad / iPhone): マイク入力(
AVAudioEngineまたはgetUserMedia)、PCM/Opus エンコード、スピーカー再生のみ。ネイティブアプリでも PWA でも実装可能 - 🌐 Edge / Gateway: TLS 終端、WebSocket アップグレード、レート制限、JWT 検証。Cloudflare + Nginx/Caddy の組み合わせが定石
- ⚙️ Application Server: FastAPI などで REST + WebSocket を提供し、長尺 ASR は Celery + Redis で非同期実行。リアルタイム TTS はチャンク単位でストリームを橋渡し
- 🔥 Inference (GPU): VibeVoice-ASR-7B / Realtime-0.5B を vLLM で推論。デプロイ先は HF Inference Endpoints / RunPod / Modal / 自宅 GPU + Tailscale など
- 💾 Storage / State: 音声は S3 互換のオブジェクトストレージ、トランスクリプトは PostgreSQL、ジョブ状態とレート制限カウンタは Redis、API トークンは Vault
想定ユースケース
| ユースケース | 端末側 | サーバ側 |
|---|---|---|
| 60分録音 → 文字起こし | 録音→アップロード→進捗を SSE で受信 | 非同期キュー → ASR-7B → 結果を DB 保存 |
| リアルタイム文字起こし | マイクストリーム送信 | WebSocket で ASR ストリーミング推論 |
| テキスト読み上げ | 文字列送信→音声受信→再生 | Realtime-0.5B で 300ms レイテンシ生成 |
このパターンの利点
- 端末側のバッテリ・発熱を抑制: 推論は重いので GPU 任せにする
- モデル更新がサーバ側で完結: アプリ更新不要で改良版に追従できる
- マルチデバイス対応: 同じバックエンドを iPad / iPhone / Web ブラウザ / Mac で共有可能
- API キーの安全管理: 端末にウェイトもキーも置かないので漏洩リスクを最小化
応用: 準リアルタイム議事録生成への発展構成
VibeVoice-ASR は本来「60分の長尺音声を 1 パスで処理して精度を出す」モデルであり、Whisper のように低遅延ストリーミング向けには設計されていない。それでも、議事録ユースケースで「会議中の暫定字幕」と「会議終了直後の高品質確定版」を両立させるには、3 レーン並走の構成が有効である。
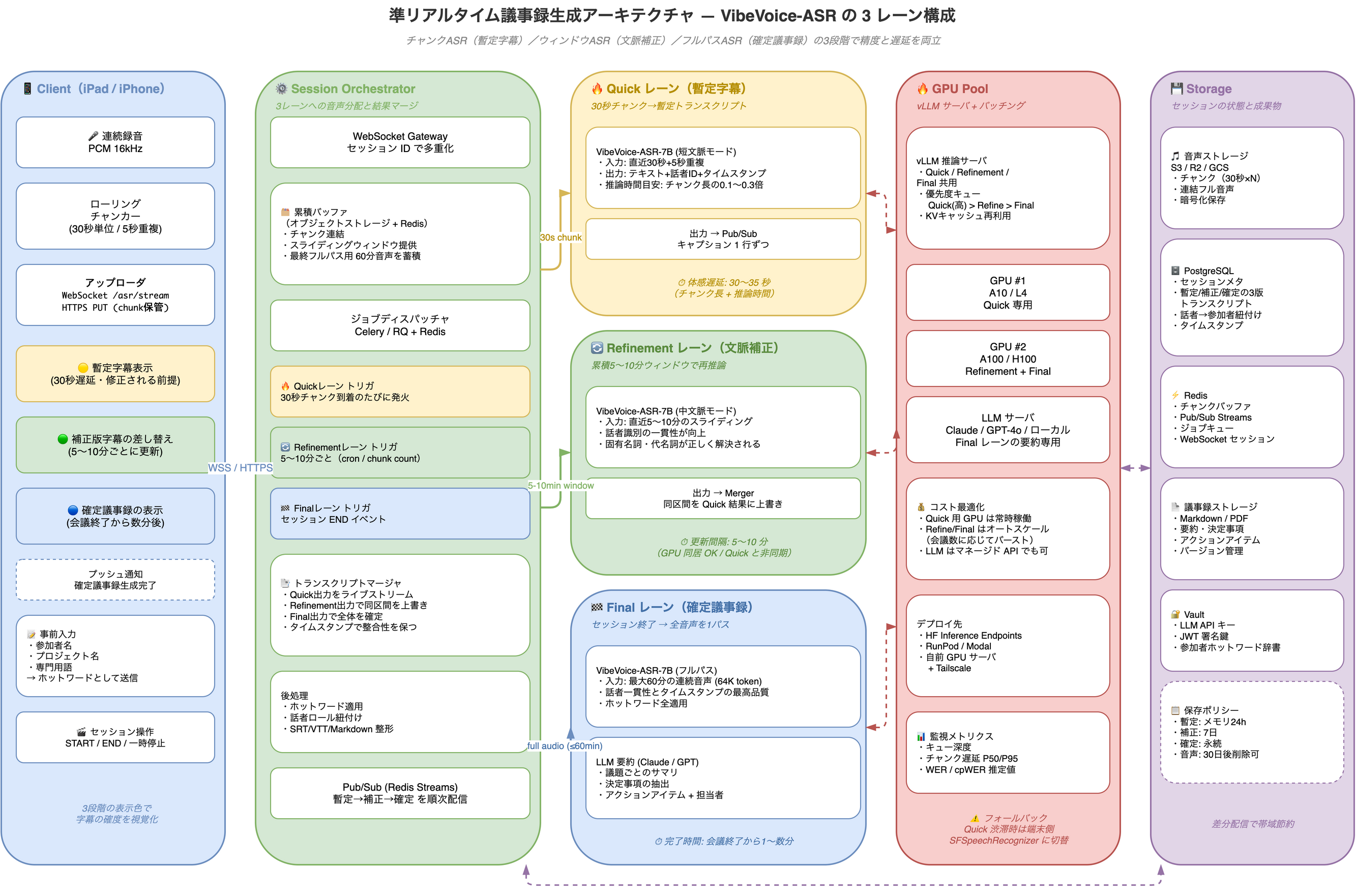
3 つのレーン
| レーン | 入力 | 役割 | 体感遅延 | 表示 |
|---|---|---|---|---|
| 🔥 Quick | 直近 30 秒チャンク(5 秒重複) | 暫定字幕の即時生成 | 30〜35 秒 | 🟡 黄色 = 暫定 |
| 🔄 Refinement | 直近 5〜10 分のスライディング | 文脈で固有名詞・代名詞を解決 | 5〜10 分ごとに更新 | 🟢 緑 = 補正済み |
| 🏁 Final | セッション全音声(最大 60 分) | 確定議事録 + LLM 要約 | 会議終了から数分 | 🔵 青 = 確定 |
クライアント側は色で確度を視覚化することで、まだ確定していない情報を読者が判断できるようにする。
Session Orchestrator の責務
30秒チャンク到着 → 累積バッファに追加
├→ Quick レーン即時発火(毎回)
├→ Refinement レーン条件発火(5〜10分経過 or N チャンクごと)
└→ END イベントで Final レーン発火
トランスクリプトマージャ:
Quick 結果でライブストリーム開始
→ Refinement 結果で同区間を上書き(タイムスタンプ整合)
→ Final 結果で全体を確定置換
Redis Streams などの Pub/Sub で「暫定 → 補正 → 確定」を同じ WebSocket チャネルから順次配信すれば、クライアントは差分だけ受け取って画面を更新できる。
GPU プールと優先度設計
3 レーンが同じ vLLM サーバを共有する場合、優先度キューで「Quick > Refine > Final」を守ることが重要だ。Quick が遅延すると暫定字幕の体験が崩れるため、最低 1 枚は Quick 専用 GPU を確保する設計が現実的。
| GPU 用途 | 推奨スペック | スケーリング |
|---|---|---|
| Quick 専用 | A10 / L4(軽量・常時稼働) | 会議数に応じて水平 |
| Refinement + Final | A100 / H100(バースト) | オートスケール |
| LLM 要約 | マネージド API(Claude / GPT)でも可 | API 課金で十分 |
Quick レーンが渋滞した場合のフォールバックとして、端末側 SFSpeechRecognizer(iPad/iPhone のオフライン ASR)に切り替える設計も組み込んでおくと、ネットワーク劣化時にも字幕表示が止まらない。
ホットワードでの精度向上
VibeVoice-ASR の強みであるカスタムホットワードは、議事録ユースケースで特に効果を発揮する:
- 参加者名(「田中」「佐藤」)
- プロジェクト名・製品名・部署略称
- 業界専門用語
セッション開始時にこれらを Vault 内のホットワード辞書から読み込んで全レーンに渡せば、固有名詞の認識精度が大幅に向上する。
ストレージ保存ポリシー
3 版のトランスクリプトを永続化するとコストが嵩むため、TTL を分けて運用するのが定石:
- 暫定: メモリ + 24 時間で削除(Redis)
- 補正: 7 日保存(PostgreSQL)
- 確定: 永続保存(PostgreSQL + Markdown ファイル)
- 元音声: 30 日後にアーカイブ層へ、もしくは削除可能(GDPR・社内規定対応)
この構成の限界と注意点
- 30 秒の体感遅延は許容できないユースケース(同時通訳的な使い方)には不向き
- ASR-7B のチャンク推論は本来の使い方ではないため、短文脈での精度は Whisper streaming と比較して必ずしも優位とは限らない(要ベンチマーク)
- GPU コスト: 3 レーン並走は単純比較で 1 レーンの 2〜3 倍。会議数に応じて Refinement/Final をオートスケールしてコスト最適化する
- プライバシー: 会議音声は機密性が高いため、暗号化保存と RBAC は必須
AWS マネージドサービスへのマッピング
3 レーン構成を AWS にデプロイする場合の典型構成。サーバレス(API Gateway / Lambda / Step Functions / SQS / Bedrock)と GPU 常駐(ECS on EC2 / SageMaker)を使い分ける。
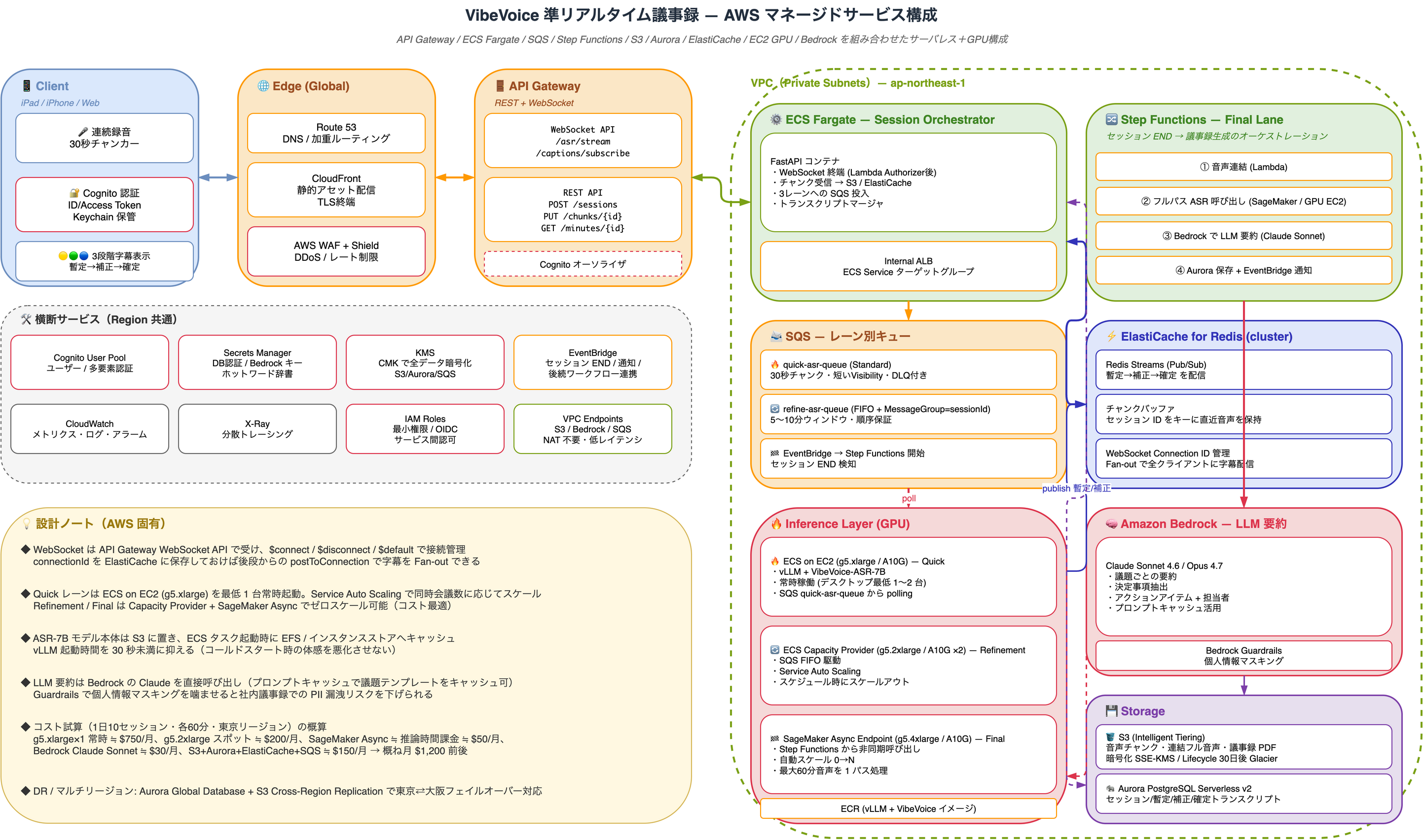
サービス対応表
| 役割 | 採用サービス | 備考 |
|---|---|---|
| 認証 | Cognito User Pool + API Gateway オーソライザ | iOS は Keychain にトークン保管 |
| エッジ | Route 53 / CloudFront / WAF / Shield | DDoS と TLS 終端 |
| API | API Gateway(REST + WebSocket) | $connect/$disconnect 管理、postToConnection で字幕配信 |
| アプリ | ECS Fargate(Session Orchestrator) | FastAPI コンテナ、Internal ALB |
| Quick レーン | ECS on EC2 g5.xlarge (A10G) | 常時稼働、Service Auto Scaling |
| Refinement レーン | ECS Capacity Provider g5.2xlarge | SQS FIFO 駆動 / スポット可 |
| Final レーン | SageMaker Async Endpoint | ゼロスケール対応、Step Functions から呼び出し |
| ジョブキュー | SQS Standard / FIFO + DLQ | FIFO は MessageGroupId=sessionId で順序保証 |
| オーケストレーション | Step Functions | END イベント → 連結 → ASR → Bedrock → 保存 |
| Pub/Sub・キャッシュ | ElastiCache for Redis (cluster) | Redis Streams で字幕 Fan-out |
| LLM 要約 | Amazon Bedrock(Claude Sonnet 4.6) | Guardrails で PII マスキング |
| 音声 / 議事録 | S3 Intelligent Tiering + SSE-KMS | Lifecycle で 30 日後 Glacier |
| トランスクリプト DB | Aurora PostgreSQL Serverless v2 | 暫定/補正/確定の 3 版を保存 |
| イベント連携 | EventBridge | END 検知 / 後続ワークフロー(Slack 通知等) |
| 機密情報 | Secrets Manager + KMS | Bedrock キー、ホットワード辞書 |
| 監視 | CloudWatch + X-Ray | キュー深度・遅延 P50/P95 |
| ネットワーク | VPC + VPC Endpoints | S3 / Bedrock / SQS は NAT を経由しない |
AWS 固有の設計ポイント
- WebSocket Fan-out: API Gateway WebSocket API の
connectionIdを ElastiCache に保存しておけば、Inference 側からのpostToConnectionで同じセッションを見ている全クライアントに字幕を一斉配信できる - モデルキャッシュ: VibeVoice-ASR のウェイトは S3 に置き、ECS タスク起動時に EFS / インスタンスストアへキャッシュ。vLLM コールドスタートを 30 秒未満に抑えるのが体感のカギ
- コスト最適化: Quick は常時稼働で固定費、Refinement / Final は SQS 駆動 + ゼロスケールで完全な変動費にできる
- マルチリージョン DR: Aurora Global Database + S3 Cross-Region Replication で東京 ⇄ 大阪フェイルオーバー
コスト試算(東京リージョン・1 日 10 セッション × 60 分の場合)
| 項目 | 概算(月額 USD) |
|---|---|
| g5.xlarge × 1 常時稼働(Quick) | $750 |
| g5.2xlarge スポット(Refinement、ピーク時) | $200 |
| SageMaker Async Endpoint(Final、推論時間課金) | $50 |
| Bedrock Claude Sonnet 4.6(要約) | $30 |
| S3 + Aurora Serverless v2 + ElastiCache + SQS + API Gateway | $150 |
| 合計 | 約 $1,200 / 月 |
GPU 常時稼働分が支配的なので、夜間の Quick GPU を停止する運用ができれば 30〜40% カットできる。
Bedrock を採用する理由
LLM 要約に外部 API(Claude API 直叩き)を使うこともできるが、Bedrock を選ぶ動機は次の通り:
- VPC 内で完結: 議事録テキストを VPC 外に出さずに済む(コンプライアンス要件で重要)
- IAM で認可: API キー管理が不要、IAM Role のみで Step Functions から呼べる
- Guardrails: 会議に含まれる個人情報・機密語のマスキングを宣言的に設定できる
- プロンプトキャッシュ: 議事録テンプレート部分はキャッシュ対象にして要約コストを削減
iPad / iPhone クライアントのプログラム構成
クライアント側は Swift 6 + SwiftUI ネイティブアプリを推奨する。理由は次の通り:
- 連続録音とバックグラウンド動作が PWA より格段に安定(Safari は Tab 切替で
getUserMediaが止まる) - Audio Session の細かい制御(Bluetooth、AirPods、CarPlay)が必要
- APNs プッシュ通知で「議事録できました」を確実に届けたい
- **Swift Concurrency(async-await + Actor)**が音声パイプラインに極めて自然にハマる
4 層構成(Clean Architecture)
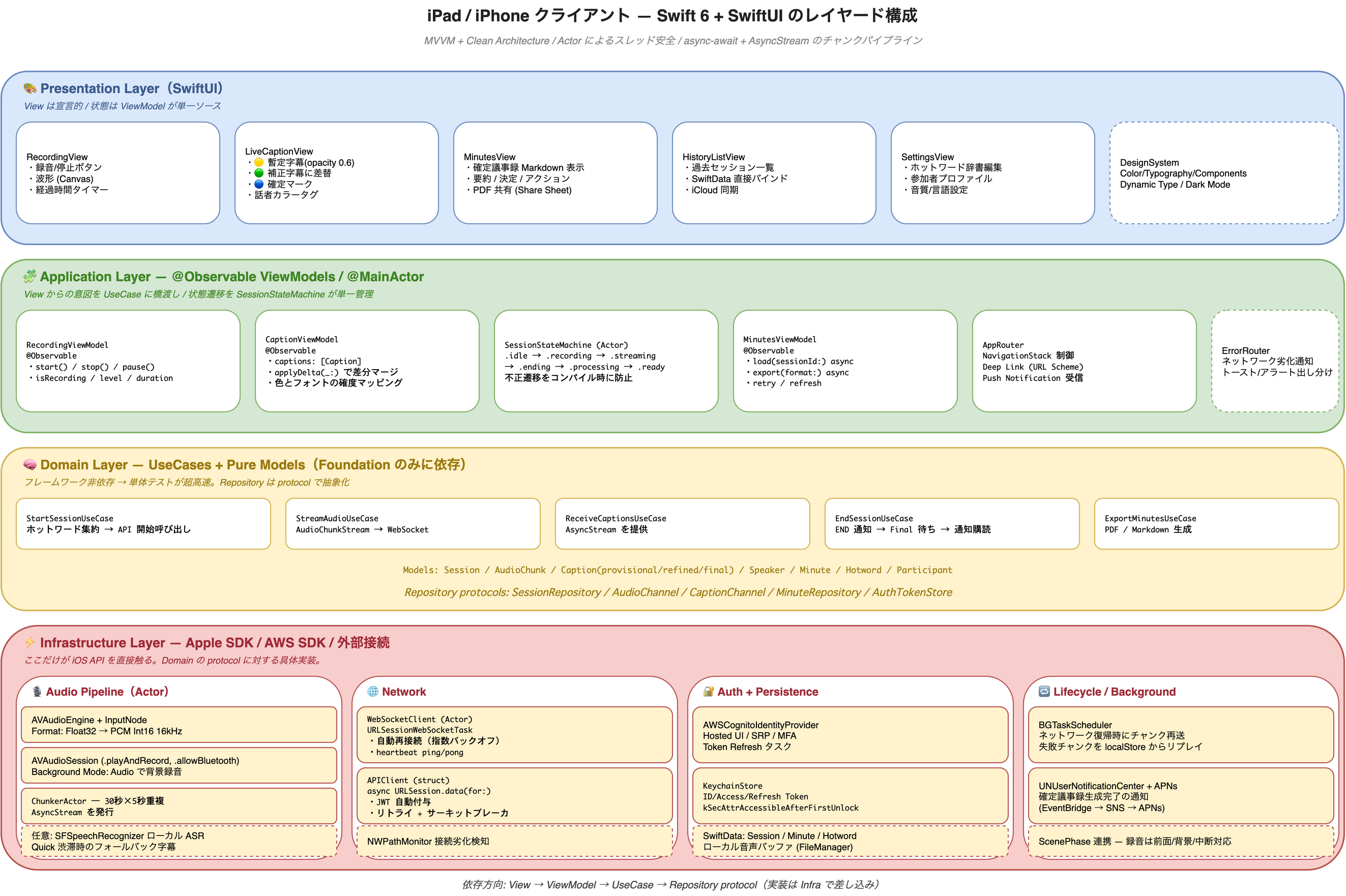
| 層 | 役割 | 主な要素 |
|---|---|---|
| 🎨 Presentation | SwiftUI View / DesignSystem | RecordingView / LiveCaptionView / MinutesView / HistoryListView / SettingsView |
| 🧩 Application | @Observable ViewModel と状態遷移 | RecordingViewModel / CaptionViewModel / SessionStateMachine(Actor) / AppRouter |
| 🧠 Domain | UseCase + ピュアモデル(Foundation のみ) | StartSessionUseCase / StreamAudioUseCase / ReceiveCaptionsUseCase / EndSessionUseCase / Repository protocol 群 |
| ⚡ Infrastructure | Apple SDK / AWS SDK の具体実装 | AVAudioEngine / URLSessionWebSocketTask / Cognito / Keychain / SwiftData / BGTaskScheduler |
依存方向は 上 → 下の単方向。Infrastructure を protocol の裏に隠すことで、Domain と Application は単体テストがフレームワーク非依存・高速で回る。
キーモジュールの設計
🎙 Audio Pipeline(Actor で並行安全)
| |
AVAudioSessionカテゴリは.playAndRecord+.allowBluetoothInfo.plistのUIBackgroundModesにaudioを追加し、ロック中も録音継続- 中断(電話・Siri)は
AVAudioSession.interruptionNotificationでハンドル
🌐 WebSocket クライアント(再接続ロジック内蔵)
| |
- API Gateway WebSocket への接続は 指数バックオフで自動再接続
- ネットワーク劣化は
NWPathMonitorで先回り検知して UI に表示 - 切断中に発生したチャンクはローカルキューに溜め、再接続後に送る
🔐 認証は Cognito + Keychain
AWSCognitoIdentityProviderで Hosted UI / SRP / MFA- アクセストークンは Keychain (
kSecAttrAccessibleAfterFirstUnlock) に保存 - リクエスト送信時に JWT を毎回自動付与(
URLRequestAdapter / Interceptor) - リフレッシュは別 Task でバックグラウンド実行
🟡🟢🔵 字幕の差分マージ
サーバから WebSocket で来る CaptionEvent はタイムスタンプ付きで届く:
| |
- 暫定(黄色・opacity 0.6)→ 補正(緑・通常)→ 確定(青・太字)と段階表示
- SwiftUI 側は
@Observableのおかげで自動再描画
🔁 バックグラウンドとプッシュ通知
| 状況 | 仕組み |
|---|---|
| アプリが背景に回る | UIBackgroundModes: audio で録音継続 |
| 電話で中断 | AVAudioSession.interruptionNotification でセッション保留→復帰 |
| ネットワーク切断中の録音 | チャンクを FileManager のローカル音声バッファに保存 |
| 復帰時の再送 | BGTaskScheduler で再アップロード |
| 確定議事録の通知 | EventBridge → SNS → APNs → UNUserNotificationCenter |
モジュール分割(Swift Package)
Sources/
├── App/ # @main エントリ
├── Features/
│ ├── Recording/
│ ├── Captions/
│ ├── Minutes/
│ └── History/
├── DesignSystem/ # Color, Typography, Components
├── Domain/ # UseCase + Models + Repository protocols
├── Data/ # Repository 実装
├── Infrastructure/
│ ├── Audio/
│ ├── Network/
│ ├── Auth/
│ └── Persistence/
└── TestSupport/ # Mock Repository
Package.swift で Feature ごとにターゲット分離すれば、ビルドが並列化されて開発速度が上がる。
iPadOS 特有の配慮
- Stage Manager / Slide Over で複数ウィンドウ対応 →
WindowGroupで複数セッションを同時表示 - Apple Pencil でメモを字幕に追記 →
PencilKitで議事録に手書きアノテーション - External Display に確定議事録を表示しつつ iPad 本体は録音インジケータに専念
- キーボードショートカット: スペースで録音 START/STOP、
⌘Eで議事録エクスポート
テスト戦略
- Domain UseCase: フレームワーク非依存なので Swift Testing で 数百件を 1 秒未満で実行
- Application ViewModel: モック Repository を差し込み、状態遷移を
#expectで検証 - Infrastructure: 録音はシミュレータでの手動 + UI Test で代替(
AVAudioEngineのモックは現実的でない) - WebSocket:
URLProtocolをスタブ化して切断・遅延・再送シナリオを再現
まとめ — 何ができて、何ができないか
VibeVoice の 2026-04-29 時点で利用可能なもの:
- ✅ VibeVoice-ASR-7B: 60分一発文字起こし/話者識別+タイムスタンプ/50言語+ホットワード対応/Hugging Face Transformers 統合済み
- ✅ VibeVoice-Realtime-0.5B: 約300msレイテンシ/ストリーミング入力/9言語ボイス/Colab で即時実行可
現状利用が制限されているもの:
- ⚠️ VibeVoice-TTS-1.5B: 90分・4話者の長尺TTSはコードが削除済み(悪用報告のため)
「ローカルで完全無料で動く長尺ASR」という用途では、現状 VibeVoice-ASR が最有力候補と言える。一方、長尺マルチ話者 TTS については、Microsoft 自身が責任ある AI の観点から提供を停止している点を踏まえて代替手段を検討する必要がある。