サーバー監視は「死活監視 + リソース監視」の時代から、「メトリクス + ログ + トレース」を 1 つの画面で相関分析するオブザーバビリティの時代に移りました。クラウドネイティブ環境では、Grafana Labs の OSS スタック(Prometheus + Loki + Grafana + Alloy)が、コスト・自由度・運用ノウハウの蓄積において事実上の王道になっています。
この記事では、なぜこの組み合わせが現代の標準なのか、各コンポーネントがどう役割分担しているのか、そして最小構成から本番運用までの全体像を整理します。
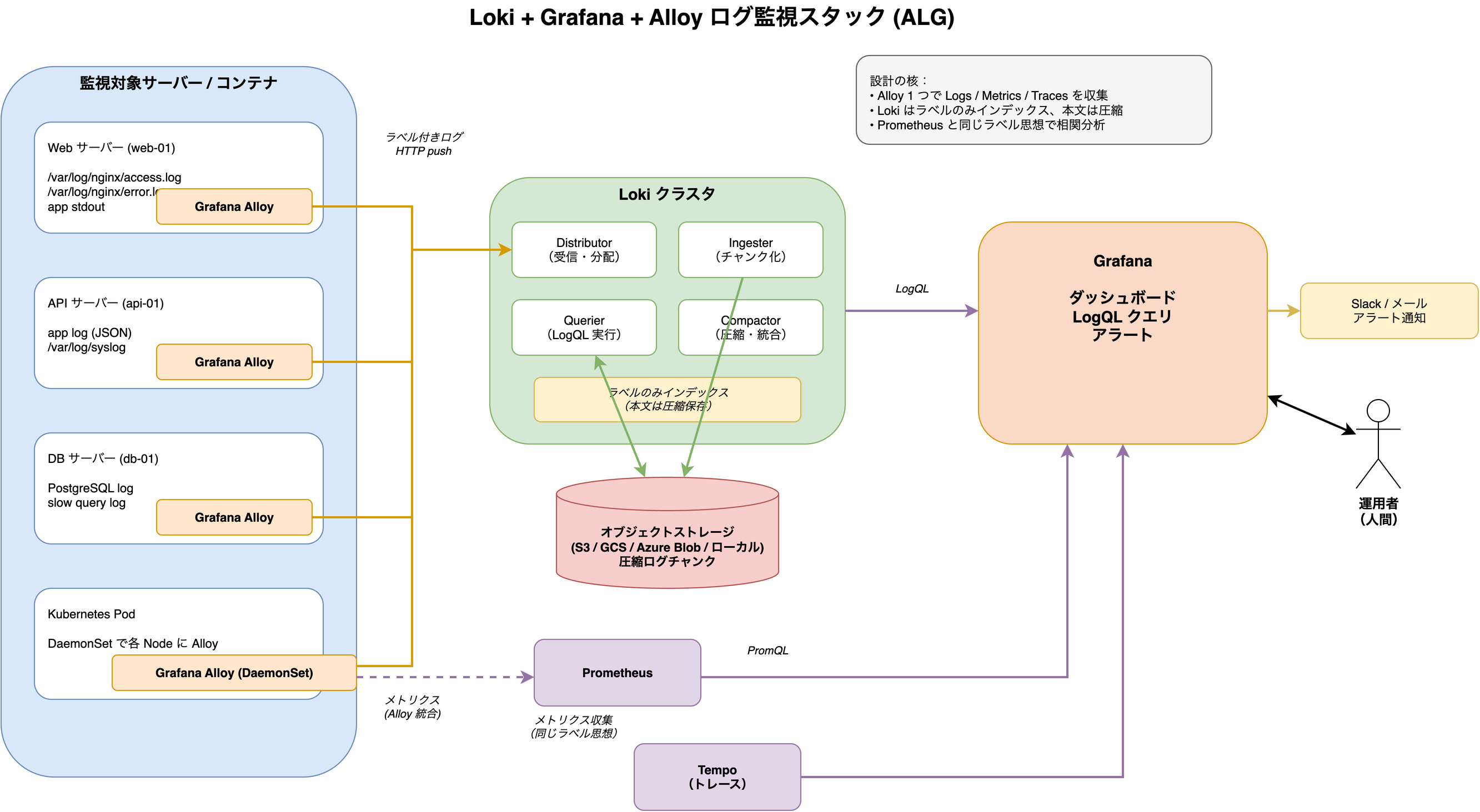
なぜこの構成が「王道」なのか
サーバー監視の選択肢は大きく分けて 3 系統あります。
| カテゴリ | 代表例 | 特徴 |
|---|---|---|
| OSS スタック(Grafana Labs) | Prometheus + Loki + Grafana + Alloy | 無料、自由度高、運用責任は自分で |
| OSS スタック(Elastic) | Elasticsearch + Logstash + Kibana + Beats | 全文検索が強力、コストとリソース消費が大 |
| SaaS | Datadog、New Relic、Grafana Cloud | 楽だが高価、データ主権がない |
このうち Prometheus + Loki + Grafana + Alloy が王道とされる理由:
- Prometheus が事実上のメトリクス標準 — Kubernetes が同梱する
kube-state-metricsや CNCF プロジェクトの大半が Prometheus 形式でメトリクスを公開 - Loki がコスト効率で ELK を凌駕 — ラベルのみインデックスで運用コストが数分の一
- Grafana が可視化のデファクト — どのデータソース(CloudWatch / Prometheus / Loki / Datadog)でも同じ UI で扱える
- Alloy で収集エージェントが 1 種類に統合された — メトリクス・ログ・トレース別々に Agent を入れていた時代から進化
- 同じラベル思想でメトリクスとログが結合 — Loki は最初から「ログ版 Prometheus」として設計され、相関分析が標準動線
4 コンポーネントの役割分担
① Grafana Alloy(統合収集エージェント)
各サーバー / コンテナにインストールされる唯一のエージェント。メトリクス・ログ・トレースを 1 プロセスで収集して、それぞれの宛先に振り分けます。
- 旧 Grafana Agent + Promtail + OpenTelemetry Collector の機能を統合
- Promtail は 2026-03-02 で EOL — 新規構築・既存環境ともに Alloy が標準
- 設定ファイル形式は HCL ライクな Alloy syntax
alloy convertコマンドで Promtail 設定を自動変換可能
| |
エージェント運用の観点では、**「マシンに 1 種類のバイナリだけインストールすればよい」**ことが Alloy 統合の最大の恩恵です。
② Prometheus(メトリクスの収集・保存・クエリ)
時系列データベース + クエリエンジン + アラートエンジンが一体化したコンポーネント。
- Pull 型 — Prometheus 側がエクスポーター(
/metricsエンドポイント)を定期スクレイプ node_exporter、cadvisor、kube-state-metricsなどのエクスポーターが豊富 — CPU・メモリ・ディスク・ネットワーク・コンテナ・K8s リソースを標準で収集可能- PromQL という時系列に特化したクエリ言語
- アラートルール を YAML で定義 → Alertmanager 経由で Slack / メール / PagerDuty へ
- 長期保存は外部にオフロード — Thanos / Mimir / Cortex で数ヶ月〜数年のデータを保持可能
| |
Prometheus が**システムの「異常検知エンジン」**を担うため、本番運用では事実上必須です。
③ Loki(ログの集約・保存・検索)
「ログ版 Prometheus」として設計された軽量ログアグリゲーション。
- ラベルのみインデックス — 全文インデックスを作らないので、ストレージとメモリが劇的に少ない
- 本文は圧縮して object store に保存 — S3 / GCS / Azure Blob / ローカル
- LogQL で検索 — Prometheus と同じラベルセレクタの語彙
- マルチテナント対応 — 大規模運用ではテナント分離可能
- retention をラベル単位で制御 — エラーログは長期、デバッグは短期、など
Prometheus と全く同じラベル({job, env, host, ...})でログが識別されるため、メトリクスから同じセレクタでログにジャンプできます。
④ Grafana(統合ダッシュボード・アラート UI)
すべてのデータソースを束ねる可視化レイヤー。
- データソース不問 — Prometheus / Loki / Tempo / CloudWatch / Datadog / SQL DB すべて同じ UI
- ダッシュボード — JSON / YAML でコード化、Git 管理可能
- アラート — Prometheus 由来のアラートと Grafana ネイティブアラートを統合管理
- Explore モード — 即興で PromQL / LogQL を投げて相関分析
- メトリクス → ログのドリルダウンが 1 クリックで完結(Data link 機能)
トレースを足すなら Tempo(オプション)
マイクロサービス環境では分散トレースが重要になります。Grafana Labs スタックでは Tempo が担当:
- OpenTelemetry / Jaeger / Zipkin プロトコル対応
- Object store ベースで Loki と同じ低コスト思想
- Trace ID で Loki ログと紐付け(ログに
trace_id=...を仕込めば、ログから該当トレースへジャンプ)
ただし最初の段階では Prometheus + Loki だけで十分です。トレースは「マイクロサービス化が進んでから追加」で問題ありません。
ELK / SaaS との比較
| 観点 | Prometheus + Loki + Grafana | ELK | Datadog |
|---|---|---|---|
| メトリクス | Prometheus(標準) | Metricbeat(やや弱い) | 標準 |
| ログ | Loki(軽量) | Elasticsearch(高機能・重) | 標準 |
| トレース | Tempo | APM | 標準 |
| 可視化 UI | Grafana | Kibana | 専用 UI |
| インデックス戦略 | ラベルのみ | ログ全文 | 全文 |
| 運用コスト | 低(OSS、自前運用) | 中〜高 | 高(SaaS) |
| 学習コスト | PromQL + LogQL | DSL + KQL | 専用 UI |
| ベンダーロック | なし(OSS) | なし(OSS) | あり |
| SaaS 化の選択肢 | Grafana Cloud | Elastic Cloud | Datadog のみ |
OSS で自前運用するなら Prometheus + Loki + Grafana がコスト最適。「運用したくない」なら Grafana Cloud で同じスタックを SaaS 化する道もあり、移行性が高いです。
docker-compose で 5 分で起動する最小構成
ローカルで全体を動かす最小例:
| |
| |
| |
docker compose up -d で http://localhost:3000 を開けば、両データソースが繋がった Grafana が起動します。
監視の 3 階層と各コンポーネントの守備範囲
実用的な監視は **「死活 → リソース → アプリケーション」**の 3 階層で考えると整理しやすいです。
| 階層 | 監視対象 | 主な担当 |
|---|---|---|
| 死活監視 | Ping、HTTP ヘルスチェック | Prometheus(blackbox_exporter) |
| リソース監視 | CPU、メモリ、ディスク、ネットワーク | Prometheus(node_exporter、cadvisor) |
| アプリ監視 | エラーログ、レスポンスタイム、ビジネスメトリクス | Prometheus(独自エクスポーター) + Loki |
「ログだけあればいい」というケースはほぼなく、3 階層をカバーするにはメトリクスとログの両方が必須です。
アラート設計と担当者への通知 — 運用の核
監視スタックは「グラフを見る」のが本体ではなく、異常を自動検知して担当者に届けるのが本来の目的です。Prometheus + Grafana スタックは、ルール定義から通知ルーティング、オンコール体制まで OSS で一気通貫で組めます。
アラートシステムの全体像
| |
1. アラートルール定義(PromQL)
Prometheus のアラートは YAML で定義:
| |
ポイント:
for: 5mで短期スパイクを除外 — 瞬間的な揺れでは通知しないlabels.severityとlabels.teamがルーティングのキーannotations.runbookに対処手順 URL を入れるのが定石
2. ログベースアラート(LogQL)
Loki のログでも同じ仕組みでアラートを発火できます:
| |
「特定エラー文字列が一定数を超えたら」という運用要件をコード化して再現可能にできます。
3. Alertmanager によるルーティング
発火したアラートはラベルを見て担当者に振り分けられます:
| |
これで以下の運用が実現します:
- 平日昼間: backend チームの critical → PagerDuty +
#backend-alerts - 夜間・休日: 全 critical → オンコール担当者へ電話 / SMS
- warning: チーム別 Slack チャンネル
4. Grafana Alerting(UI ベース、近年の主流)
Grafana 8 以降の Unified Alerting は UI でルール作成・編集が可能で、Alertmanager と同等のルーティング機能を内蔵。
- Prometheus / Loki / CloudWatch を横断したアラート定義が可能
- ダッシュボードのパネルから「このグラフからアラートを作る」が 1 クリック
- 通知履歴・サイレンス・状態の UI 管理
- Grafana OnCall(OSS / Cloud)と統合してオンコールローテも管理可能
YAML 派は Prometheus 側、UI 派は Grafana 側、両方を併用もできます。近年は「Grafana Alerting に集約する」運用が増えています。
5. オンコール体制との統合
「夜中に誰が起きるか」を管理するのが On-call 系ツール:
| ツール | 価格目安 | 特徴 |
|---|---|---|
| PagerDuty | $21〜/ユーザー/月 | 業界標準、エスカレーション豊富 |
| Opsgenie | $9〜/ユーザー/月 | Atlassian 製、Jira 連携 |
| Grafana OnCall | OSS 版無料、Cloud 版あり | Grafana スタックと一体化、コスト最適 |
| AWS Incident Manager | 従量課金 | AWS ネイティブ |
これらが Alertmanager / Grafana Alerting からの webhook を受けて、ローテーションに従って担当者に SMS / 電話 / プッシュ通知します。「2 分応答なければ次の人にエスカレーション」のようなルールも組めます。
6. 通知に含めるべき情報
良いアラート通知の条件:
- 何が起きたか(symptom) —
API エラー率 5% 超過 - どのリソースか(context) —
cluster=prod, service=order-api - どれくらいの値か —
現在 8.2%, 閾値 5% - 対処手順 URL(runbook) — wiki / Notion / Confluence へのリンク
- 関連ダッシュボード URL — 1 クリックで詳細を見られる
- 影響範囲(business impact) —
ユーザー注文機能が部分的に失敗中
annotations にこれらを構造化して入れると、通知を見た担当者が 30 秒で状況把握できます。
7. アラート疲れを避ける鉄則
- 発火条件を厳しく —
for: 5mで短期フラッピング除外 - 症状ベース(symptom-based)アラートを優先 — 「ディスク 80%」より「書き込みエラー率上昇」
- グループ化 —
group_by: [alertname, cluster]で同種アラートを 1 通知にまとめる - 抑制(inhibition) — 親アラート発火中は子アラートを抑制(ノードダウン中の Pod 不足は通知しない)
- サイレンス — メンテ時は一時ミュート
- SLO ベース — バーンレート(エラーバジェット消費速度)で「SLO 違反のペース」を見る方が、瞬間値より実用的
このアラート設計が**「監視ダッシュボードはあるが誰も見てない」状態を防ぐ最後の砦**です。逆に言えば、アラート設計が雑だとどんな立派なダッシュボードも実運用では機能しません。
メトリクスからログへドリルダウンする実践フロー
王道スタックの真価は「異常検知 → ログでの原因分析」が画面遷移なく繋がる点です。
シナリオ: API のレスポンスタイムが急に悪化した
- Grafana ダッシュボードで
histogram_quantile(0.95, ...)の 95%ile レイテンシが 200ms → 2000ms に急上昇したと検知 - グラフをクリック → 時間範囲・該当ホストを自動セットして Loki Explore に遷移
{job="api", host="api-01"}のログを LogQL で表示|= "ERROR"でエラー絞込、または| json | response_time_ms > 1000で遅いリクエストだけ抽出- スタックトレースから「DB 接続プール枯渇」が原因と特定
- 必要なら
count_over_time({job="api"} |= "connection pool exhausted" [1m])でメトリクス化してアラート追加
このフローが同じ Grafana 画面内で完結するのが、Prometheus + Loki セット運用の核心的な価値です。
Kubernetes での標準構成
クラウドネイティブ環境では kube-prometheus-stack(Helm chart) が事実上の標準セットアップ:
| |
これで以下が一括導入されます:
- Prometheus Operator(Prometheus を K8s リソースとして管理)
- Prometheus 本体
- Alertmanager
- Grafana(kube-state-metrics ダッシュボード組み込み済み)
- node-exporter(DaemonSet)
- kube-state-metrics
ログ側は別途 Loki と Alloy を入れます:
| |
K8s 環境では Pod のラベルが Prometheus / Loki 両方のラベルにそのまま伝播するため、ラベル設計を悩む必要がほぼなくなるのが大きな利点です。
AWS 環境での選び方 — CloudWatch かハイブリッドか
「AWS なら CloudWatch でいいのでは?」という疑問は当然あります。実用上は 「CloudWatch を捨てる」のではなく「Grafana を上に乗せる」ハイブリッドが多くの AWS 環境での最適解になります。
CloudWatch の強みと弱み
強み:
- AWS サービス(RDS、Lambda、ECS、ALB、VPC Flow Logs、CloudTrail)のメトリクスがエージェント不要で自動収集
- IAM ベース認証、AWS SDK との統合
- インフラ運用不要(CloudWatch 自体が落ちる心配なし)
- CloudWatch Alarms → SNS → Lambda の連携が AWS ネイティブ
弱み:
- 大規模で急激にコスト増:
- CloudWatch Logs ingestion: $0.50/GB
- Logs Insights クエリ: $0.005/GB スキャン
- 月 1 TB のログ + 頻繁な検索で簡単に $1,000/月超
- カスタムメトリクスが高い($0.30/メトリクス/月、ラベル組合せが多いと膨張)
- ダッシュボードが貧弱(CloudWatch Dashboards は Grafana の自由度に遠く及ばない)
- クロスアカウント / マルチクラウドが面倒
- ベンダーロックイン
コスト比較の実例(100 GB/月のログ)
| 構成 | 月額(概算) |
|---|---|
| CloudWatch Logs(ingestion + 30 日保管 + クエリ) | $80〜200 |
| Loki on S3(S3 標準 + EC2 t3.medium) | 約 $35 |
TB 級になるほど差が広がります。Loki が S3 にオフロードできるのが効きます。
推奨ハイブリッド構成
| |
ポイント:
- AWS サービスメトリクスは CloudWatch から吸い上げる — Grafana のデータソースに CloudWatch を追加するか、
YACE(Yet Another CloudWatch Exporter) で Prometheus にブリッジ - アプリ・EC2・EKS のメトリクスは Alloy で直接 Prometheus に — CloudWatch を経由しないことでカスタムメトリクス料金を回避
- ログは Loki に集約 — CloudWatch Logs を捨てて S3 + Loki に統一、コスト数十分の一
AWS 公式マネージドの選択肢(運用したくない場合)
AWS 自身が OSS の Prometheus / Grafana をマネージドで提供しています。これがハイブリッドの中間解です。
Amazon Managed Service for Prometheus(AMP)
- 自分で Prometheus を運用しなくていい
- 100% PromQL 互換、Alertmanager 内蔵
- AWS IAM / SigV4 認証
- 価格: ingestion ベース、自前運用より高いが管理不要
Amazon Managed Grafana(AMG)
- マネージド Grafana
- AWS IAM Identity Center で SSO ログイン
- CloudWatch / AMP / X-Ray などのデータソースが事前設定
- 価格: ユーザー数ベース(Editor: $9/月、Viewer: $5/月)
Loki / Tempo はマネージド版なし
Loki と Tempo の AWS マネージド版は提供されていないため、
- Grafana Cloud(SaaS) で Loki / Tempo を SaaS 化
- または EKS 上で自前運用
を選ぶことになります。
Managed 中心の組み合わせ例
| |
「運用負担最小 + AWS ネイティブ統合 + Grafana の UI」のバランスが取れた構成です。
EKS / コンテナ中心環境で AMP + AMG が王道な理由
K8s 環境はメトリクスが爆発的に増える典型例です。
- Pod 数 × エクスポーター数で時系列が膨大
kube-state-metrics、cAdvisor、node-exporter、各 Controller のメトリクスが標準で出る- HPA でスケール変動するため、タグ・ラベルの組合せが動的に増える
- マルチクラスタ・マルチテナント運用ではさらに増える
CloudWatch Container Insights もあるが、Prometheus エコシステム(コミュニティダッシュボード、エクスポーター、PromQL)が使えないため、K8s 運用ノウハウとの親和性で AMP + AMG が選ばれます。
AMP(Amazon Managed Service for Prometheus)の EKS 統合
- IAM Roles for Service Accounts(IRSA) — Pod から AMP への書き込み認証を IAM ロールで付与(kube2iam 等が不要)
remote_writeで送信 — Prometheus / Alloy / ADOT が AMP のエンドポイントに書き込み、AWS SigV4 で認証kube-prometheus-stackをそのまま使える —prometheus.remoteWriteに AMP エンドポイントを設定するだけで OSS 構成と互換- PromQL 100% 互換 — オンプレ Prometheus からの移行コストがほぼゼロ
設定例(Helm values.yaml):
| |
AMG(Amazon Managed Grafana)の EKS 統合
- IAM Identity Center(旧 AWS SSO) で組織 SSO ログイン — 個別ユーザー管理不要
- AMP / CloudWatch / X-Ray のデータソースが事前統合 — Workspace 作成時に自動セットアップ
- AWS PrivateLink で VPC からのプライベート接続可能 — オフィス → VPN → AMG が現実的
- Plugin インストール はマネージド版で許可されたものに限定 — エンタープライズプラグイン(Splunk 等)は別途課金
収集エージェントの選択: ADOT vs Alloy
EKS では収集エージェントが 2 系統:
| 選択肢 | 強み | 弱み |
|---|---|---|
| AWS Distro for OpenTelemetry(ADOT) | AWS 公式、AMP / X-Ray / CloudWatch にネイティブ統合、AWS サポート対象 | ログ収集(Loki 連携)は弱い、設定が冗長 |
| Grafana Alloy | メトリクス・ログ・トレースを 1 エージェント、Loki / Tempo と一貫性、Promtail からの移行ツールあり | AWS サポート対象外、AMP への送信は SigV4 で別途設定必要 |
メトリクスだけなら ADOT、ログも Loki に集約するなら Alloy が選択基準です。
料金感(東京リージョンの目安)
- AMP: $0.90 / 1 億サンプル ingestion + $0.03 / GB クエリスキャン
- 100 ノードクラスタで月 50M サンプル/時間 ingestion = 約 $32/月
- AMG: Editor $9 / ユーザー、Viewer $5 / ユーザー
- Editor 5 名 + Viewer 20 名 = $145/月
- Loki: マネージド版なし → Grafana Cloud Loki または EKS 自前運用
- Grafana Cloud Free tier: 50 GB ログ/月まで無料
CloudWatch Container Insights のフル運用や、Datadog などの SaaS と比較すると圧倒的に安く、かつ OSS 互換で移行性も高い構成です。
AMP + AMG の制約
- AMP のクエリ性能チューニング余地が小さい — マネージドゆえにパラメータ制限あり、超大規模クラスタでは自前 Mimir / Thanos を検討
- AMG のダッシュボード API 自動化に制限 — Terraform / Crossplane で扱いにくいケースあり
- リージョン・VPC 横断は AWS Transit Gateway / PrivateLink で別途設計
- ログは AMP の対象外 — Loki は別途自前 / Grafana Cloud で構成する必要あり
これらの制約を許容できるなら、EKS 環境では AMP + AMG + Loki(Grafana Cloud or 自前)が運用負担と機能のバランスで最適です。
AWS 環境での選び方まとめ
| 環境 | 推奨 |
|---|---|
| 小規模 AWS 単一アカウント、ログ量少 | CloudWatch 単体で十分 |
| AWS 中規模、ログ TB 級・マルチアカウント | ハイブリッド(CloudWatch + Grafana + Loki) |
| EKS / コンテナ中心、メトリクス多い | AMP + AMG + Loki(K8s 王道) |
| マルチクラウド or 将来移行検討 | 自前 Grafana Labs スタック(移植性最大) |
| 運用したくないが OSS 互換が欲しい | Grafana Cloud(フル SaaS) |
純粋に CloudWatch を捨てる構成より、**「AWS サービスは CloudWatch、それ以外は Grafana スタック、画面は Grafana で統合」**が最も多い実装パターンです。
本番運用での注意点
1. ラベルのカーディナリティ爆発(Loki / Prometheus 共通)
最大のアンチパターン。user_id や request_id のような高カーディナリティ値をラベルに入れると、両者ともインデックスが膨張して性能が劇的に劣化します。
- NG:
{job="api", user_id="12345"} - OK: ラベルは
{job, env, host, method}程度に抑え、可変値はログ本文 / メトリクス値として扱う
2. メトリクスの retention と長期保存
Prometheus 単体は数週間程度の保存が現実的。それ以上は Thanos / Mimir / Grafana Cloud で長期保存を別途構成。
3. アラート設計の規律
- Symptom-based alert(症状ベース): 「ユーザー影響があるか」を起点にアラート設計
- Cause-based alert(原因ベース)の濫用を避ける — 「ディスク使用率 80%」より「書き込みエラー率上昇」の方が実用的
- アラート疲れを避けるため、
for: 5mで短期スパイクを除外、severityで優先度分け
4. Promtail からの移行スケジュール
既存環境がある場合は EOL(2026-03-02)が過ぎているので最優先で移行:
| |
設定の 9 割は自動変換されます。
5. 認証とアクセス制御
シングルバイナリ運用ではマルチテナント機能が無効化されているケースが多い。本番では:
- Grafana の前段に OAuth Proxy / Authelia
- Prometheus / Loki への直接アクセスはネットワーク分離 or Basic 認証
- マルチテナント運用なら
auth_enabled: true+ テナントヘッダ
適しているケース・向かないケース
王道スタックが向いているケース
- Kubernetes / コンテナ環境 — エコシステムが完璧に揃う
- オンプレ + クラウド混在 — どこでも同じ構成で動く
- OSS で自前運用したい — ベンダーロックを避けたい
- コストを抑えたい — 大規模ログを object store にオフロード可能
- 将来 SaaS 化の選択肢を残したい — Grafana Cloud に同じスタックで移行可能
向かないケース
- 小規模・単一サーバーで運用負担を最小化したい — Datadog などの SaaS の方が早い
- 複雑な全文検索が主用途 — ELK の方が向いている
- すでに別の監視 SaaS が組織標準 — 移行コストに見合わない
まとめ
サーバー監視の現代的な王道は:
- Prometheus がメトリクスの異常検知エンジン
- Loki がログの低コスト集約(Prometheus と同じラベル思想で結合)
- Grafana が両者を統合した可視化・アラート UI
- Alloy が 3 つのテレメトリ(メトリクス・ログ・トレース)を 1 エージェントで収集
「Prometheus 抜きで Loki だけ」「Loki 抜きで Prometheus だけ」のどちらも成立はするものの、本来は 2 つセットで使う前提の設計で、片方だけでは現代の障害対応のスピードに追いつきません。
新規構築では Prometheus + Loki + Grafana + Alloy を最初から揃え、必要に応じて Tempo(トレース)、Mimir / Thanos(長期保存)を追加するのが、運用コストと将来の拡張性のバランスが最も取れた選択です。docker-compose で 5 分で起動できるので、まずはローカルで全体を触って感覚を掴むのが最良の入口です。