GitHub で急速に広がっている colleague-skill(titanwings/colleague-skill)というプロジェクトがある。「辞めた同僚を AI で再現する」という見た目のインパクトだけが先行しがちだが、実装を読むと本質はもっと実務的だ。このプロジェクトが企業と個人に突きつけているのは、**「判断様式そのものを組織資産にできる時代が来た」**という問いだ。
colleague-skill とは何か
titanwings/colleague-skill は、退職した同僚・前任者・メンターの仕事の進め方や話し方を、AI エージェントが呼び出せる Skill として保存するプロジェクトだ。
2026年5月時点で 18,000 stars 超、1,800 forks という数字が、この関心の高さを物語っている。
ポイントは新しいモデルを訓練しているわけではないことだ。人の暗黙知・レビュー癖・判断基準・口調を、Claude Code などで即座に呼び出せるパッケージに変換している。引き継ぎで失われがちな仕事の文脈を、実際に動く形で残すことが目的だ。
入力できるもの
Feishu・DingTalk・Slack・WeChat の会話履歴、PDF、画像、メール、Markdown、手入力テキストなど幅広いソースに対応している。
Claude Code への組み込み
インストールは軽量だ。
| |
その後、Claude Code 上でスラッシュコマンドを実行する。
/create-colleague
.claude/skills/ に配置して /create-colleague を実行するだけで、対話形式でスキルが生成される。
二層構造の設計:Work Skill と Persona
README の設計で最も重要なのは、生成物が二つのレイヤーに分かれていることだ。
| レイヤー | 内容 |
|---|---|
| Work Skill | 担当システム、技術スタック、レビュー観点、文書作法、運用フロー、経験知 |
| Persona | 話し方、優先順位、判断癖、対人スタイル、地雷 |
実行順序まで定義されている。
Receive task
→ Persona decides attitude
→ Work Skill executes
→ Output in their voice
つまり「同僚の知識を保存する」だけでなく、**「同僚の態度で、その同僚らしい手つきで仕事をさせる」**ことを目指した設計になっている。
スキル作成の流れ
SKILL.md を読むと、作成フローは驚くほどシンプルだ。最初に聞かれるのは3つだけ。
- 識別名(README 上の表記は “花名・代号”)
- 基本情報
- 性格の特徴
その後、上記のソースから資料を読み込ませる。UX は完全に「社内引き継ぎツール」の顔をしている。
さらに、生成後も進化する設計になっている。新しいファイルを追加すると差分を解析して追記し、「この人はこう言わない」「こう直して」という会話内フィードバックも反映される。version_manager.py にはロールバック機能まである。
判断はどう蓄積されていくのか — 具体的な仕組み
「判断の蓄積」と聞くとモデルの再学習やベクトル DB を想像しがちだが、実装(tools/skill_writer.py・tools/version_manager.py・prompts/merger.md・prompts/correction_handler.md)を読むと、実体は Markdown ファイルへのセクション単位のパッチ適用 + 訂正ログの追記 + ファイルコピーによる版管理という、地味で堅実な仕組みだ。
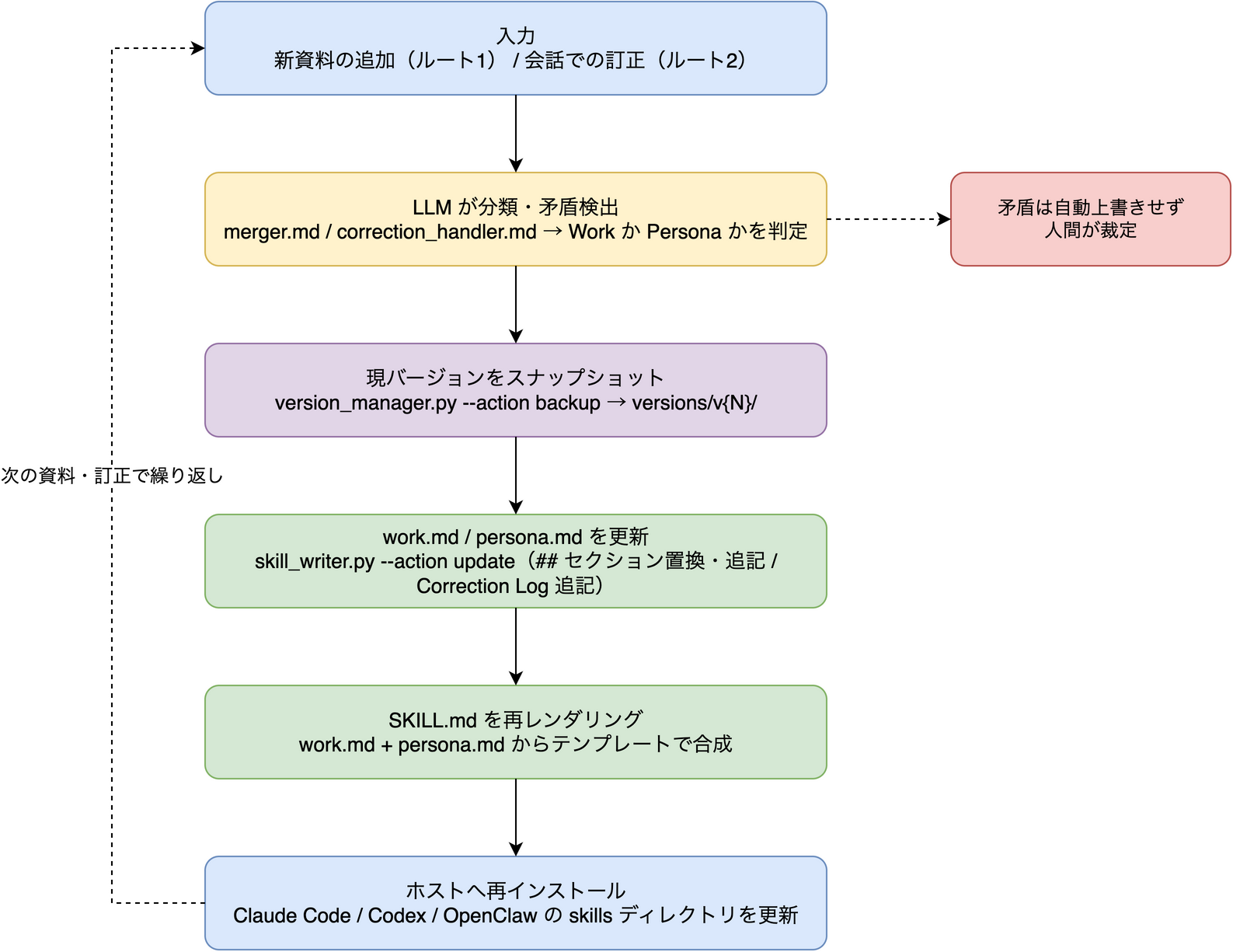
蓄積の本体は 2 つの Markdown ファイル
1 スキル = 1 ディレクトリで、レイアウトは次のとおり。
skills/colleague/{slug}/
├── work.md # 仕事の判断基準(蓄積の本体・その1)
├── persona.md # 性格・話し方(蓄積の本体・その2)
├── SKILL.md # work + persona を合成した実行用スキル(毎回再生成)
├── meta.json # version, corrections_count などのメタ情報
├── versions/ # 過去バージョンのスナップショット置き場
└── knowledge/ # 元資料(docs/ messages/ emails/)
ポイントは、蓄積される「判断」の正体が work.md と persona.md という 2 つの Markdown ファイルだということ。実行用の SKILL.md はこの 2 つからテンプレートで毎回再レンダリングされる成果物にすぎない。
ルート1:新資料の増分マージ
ユーザーが新しいファイルや会話ログを追加すると、LLM が prompts/merger.md の指示に従って各情報を「技術規範・業務知識 → work.md」「口癖・対人スタイル → persona.md」に振り分け、既存内容との 3 値判定を行う。
- 補完(新しい詳細)→ 追記
- 確認(既存と同じ)→ 無視(重複させない)
- 矛盾 → 自動で上書きせず、ユーザーに裁定を委ねる
merger.md の原則は「増分のみ追記し、既存の結論を上書きしない。矛盾は人間が決める」。判断の蓄積が LLM の自動上書きで壊れないよう、人間をコンフリクトレゾルバとして組み込んでいる。
ルート2:会話内の訂正(Correction)
「彼はそんな言い方をしない」と言うと、prompts/correction_handler.md が発言から {scene(場面), wrong(誤った挙動), correct(正しい挙動)} の 3 つ組を抽出し、訂正の帰属を判定する。
- Work 訂正(技術判断・手順)→ 置換可能な
##セクションの Markdown パッチとして work.md に反映 - Persona 訂正(話し方・対人反応)→ persona.md の
## Correction Logセクションに 1 行ずつ**追記専用(append-only)**で蓄積
| |
同時に meta.json の corrections_count がインクリメントされ、「このスキルが何回訂正されて育ったか」が一覧で見える。つまりペルソナは**「正の記述」+「否定例の蓄積」の二層**で精緻化されていく。
トリガーは明示的な指示のみ — 常駐監視も自動学習もない
「新しいファイルを追加すると差分を解析して追記」と聞くと、PC のファイルシステムを常時監視しているように見えるが、そうではない。蓄積は完全に手動・プル型だ。
書き込み経路はすべて skill_writer.py --action create / update を通り、これを呼ぶのはエージェントとの対話の中の 3 つの起動点だけ。
| 起動点 | 対話の中での例 |
|---|---|
| 初回生成 | /dot-skill「○○さんのスキルを作って」 |
| 資料追加 | 「新しいファイルがある」「これも読み込んで」 |
| 訂正 | 「彼はそんな言い方をしない」「彼ならこうする」 |
ユーザーがファイルパスを自分で指示して初めて、エージェントがそのファイルを読みに行く。常駐デーモンもファイルシステムウォッチャーも cron も存在せず、colleague-skill 自体は Markdown プロンプト + ワンショット Python スクリプト集で、プロセスとして常駐するコードがそもそもない。紛らわしい名前の slack_auto_collector.py 等の「自動採集」ツールも、ユーザーが明示的に 1 回実行する CLI であり(「自動」は「コピペ不要で API から一括取得できる」の意)、常時収集ではない。増分の分類・矛盾検出・パッチ生成は LLM の仕事(merger.md / correction_handler.md)なので、スクリプトを直接叩いても対話セッションの外では実質機能しない。
逆に重要なのは、生成されたスキルを「使っているだけ」では何も蓄積されないことだ。SKILL.md の運行規則(Persona で態度を決め → Work で実行 → その人の声で出力)は読み取り専用の実行ルールで、使用セッションからの書き戻しの仕組みを持たない。ChatGPT のメモリ機能のような「会話から勝手に覚える」自動蓄積ではなく、ユーザーが「追加して」「それは違う」と明示的にフィードバックを返した瞬間だけ知識が更新される。
知識のライフサイクルは次の 3 段階に整理できる。
- 取り込み(対話で指示)→ 資料・訂正が work.md / persona.md に蓄積
- 利用(スキル呼び出し)→ 読み取り専用、何も書き込まれない
- また取り込み → ユーザーが不満を感じて訂正を返したときだけ 1 に戻る
勝手に賢くならない代わりに勝手に変質もせず、変更は全部 versions/ に履歴が残る——統制重視の設計だ。
ただしプライバシーの論点は「ツールを動かす人の PC が監視されるか」ではなく逆方向にある。Slack コレクターは Bot Token さえあれば(要 Workspace 管理者によるインストール)、本人の同意プロセスなしに特定の同僚の発言履歴を一括取得できる。public/private channel に加え、オプションで DM まで取得 scope に含まれる。監視リスクを負うのは利用者ではなく**「蒸留される側の同僚」**であり、これは後述する「人格の無断資産化」リスクの技術的裏付けそのものだ。
マージの実装はセクション単位の置換 or 追記
skill_writer.py の merge_markdown_patch() が増分適用の実体で、アルゴリズムは単純だ。
- パッチを
##見出し単位に分割 - 既存ファイルに同名の
##見出しがあれば、そのセクションを丸ごと置換 - なければ末尾に追記
行単位の diff ではなく「セクションが知識の最小更新単位」。だからプロンプト側でも「patch は必ず置換可能な ## セクションで書け」「work.md を直接手で編集せず必ず writer 経由で更新しろ」と LLM に強制している。蓄積の整合性をプロンプト規約とスクリプトの両方で守る作りだ。
更新のたびに自動スナップショット
更新処理は毎回、現在の成果物一式を versions/v{N}/ にコピーしてからパッチを適用し、バージョン番号を v1 → v2 → … とインクリメントする。version_manager.py には次の機能がある。
--action rollback:指定バージョンを復元。その際も現状をv{X}_before_rollbackとして退避してから戻す(ロールバック自体も取り消せる)--action cleanup:保持上限 10 世代を超えた古い版を削除
Git を使わずファイルコピーだけで完結しているのは、~/.claude/skills/ のような Git 管理外の場所に置かれる前提だからだろう。
蓄積の品質を決めるのは人間の側
まとめると、蓄積機構は (1) LLM による増分の分類と矛盾検出、(2) Markdown セクションへの規律あるパッチ適用、(3) 否定例ログの append-only 追記、(4) コピーによる 10 世代の版管理 — の 4 点セットだ。逆に言えば、蓄積される判断の品質は、矛盾の裁定や「彼はこう言わない」という訂正をユーザーがどれだけ丁寧に返すかに依存する。スキルは勝手に賢くなるのではなく、フィードバックを返す人間がいて初めて育つ設計になっている。
“同僚再現"を超えたコミュニティ
README の2026年4月7日更新でコミュニティギャラリーが開設された。同僚・前任者だけでなく、著名人・思想家・メタスキルまで並ぶ。
- 56 Skills
- 20 meta-skills
- 39 contributors
colleague-skill はもはや「退職した同僚を残す道具」ではなく、人の思考様式や振る舞いを再利用可能なエージェント部品に変える汎用フレームワークになりつつある。AgentSkills のオープン標準に準拠しているため、他のエージェント環境への移植も容易だ。
企業にとっての意味
引き継ぎコストの圧縮
退職者・異動者の知識を文書ではなく「対話可能な形」で残せるなら、オンボーディングは大幅に軽くなる。特に PM・SRE・設計レビュー・顧客折衝・社内稟議のような「手順より判断」が重い業務で効果が大きい。
属人化の可視化
逆説的だが、このツールを導入すると「何が取り出せて、何が取り出せないか」が明確になる。
取り出せるもの
- レビュー観点
- よく使う判断基準
- 文書テンプレ
- 定型コミュニケーション
取り出しにくいもの
- 社内政治の読み
- 非言語の信頼
- 対立の調停
- 責任を引き取る胆力
- 例外時の優先順位づけ
つまりこのツールを導入した企業は、「誰が本当に代替可能で、誰がそうでないか」を否応なく知ることになる。
ナレッジマネジメントの再定義
従来の Wiki・議事録・FAQ のような静的文書管理ではなく、知識を実行可能な判断ユニットとして扱う。半分 業務OS化 といってもよい転換だ。
企業が雑に扱うと起きる3つの事故
1. 人格の無断資産化
仕事だけでなく性格タグや話し方も入るため、「自分のキャラまで会社資産化されるのか」という反発が起きやすい。
2. 偏見の固定化
「本人の実像」より「周囲がどう見ているか」を反映しやすい構造になっている。ある社員が “厳しいレビュー担当” として記述された瞬間、それが半永久的にプロンプト化される。人事評価と職場レピュテーションの境界が曖昧になる。
3. 知識移管と代替圧力の混線
経営は「ナレッジ継承のため」と言い、現場は「要するに代替準備では」と受け取る。ここを切り分けないと導入は失敗する。これはツール問題ではなくインセンティブ設計問題だ。
企業の判断基準:3ゾーン分類
| ゾーン | 内容 |
|---|---|
| Green Zone | 設計原則・レビュー観点・トラブル対応フロー・顧客対応テンプレ・意思決定基準・ドキュメント構造 |
| Yellow Zone | 話し方・会議での進め方・指摘の強さ・マネジメントの癖・交渉スタイル |
| Red Zone | プライベートな会話をもとにした人格推定・社内の噂や感情評価・メンタル傾向・対人好き嫌い・権力関係ベースのラベリング |
経営に必要なのは「何でも蒸留してよい」ではなく、「何を会社資産として残し、何を個人に帰属させるか」の線引きだ。
「無効化」はできても「消去」は設計されていない
線引きの議論には前提がある。「やめたくなったら止められる」ことだ。ところが実装を見ると、「colleague-skill を無効にして」という指示で止まるものと止まらないものがあり、その差がガバナンス上の急所になっている。
無効化には強度の異なる 3 つのレベルがある。
| レベル | 手段 | 効果 |
|---|---|---|
| 会話内指示 | 「無効にして」と言う | そのセッション中は呼ばれなくなる。ただしプロンプトレベルの抑制にすぎず、次のセッションでは復活する |
| ファイル撤去 | ~/.claude/skills/ から削除・退避 | 確実に動作停止。ただし手動 |
| データ消去 | ソース・生データ・履歴・全ホストのコピーを個別に削除 | これを保証する仕組みがない |
注目すべきは、colleague-skill 自体に “disable” に相当する管理コマンドが存在しないことだ。管理操作は --action list(一覧)・--action rollback(版の復元)・rm -rf(完全削除)の 3 つだけで、「有効/無効の切り替え」という中間状態が設計上なく、オンかオフ(rm -rf)かの二値になっている。
そして本質的な問題は、実行を止めても蓄積された判断資産は一切消えないことだ。
| 残る場所 | 内容 |
|---|---|
skills/colleague/{slug}/ | work.md / persona.md(蒸留済みの判断様式) |
knowledge/ | Slack ログ・メール・PDF などの生データ |
versions/ | 過去 10 世代のスナップショット(削除しても履歴から復元可能) |
| 各ホストのコピー | Claude Code / Codex / OpenClaw に配布された複製 |
蒸留された側の社員が退職時に「自分のスキルを止めてほしい」と要求できたとしても、無効化(実行停止)と消去(データ削除)は技術的に別オペレーションであり、versions/ の履歴と knowledge/ の生データが残る限り「止めた」あとも資産は再有効化できる。いわば**「忘れられる権利」に対応する削除パスが設計されていない**。
「無効化できるか」への答えは Yes だが、本質的な問いは「無効化すれば終わりなのか」で、答えは No だ。企業がこのツールを制度として導入するなら、Green / Yellow / Red の線引きとあわせて、**「本人が求めたとき、何を・どこまで・誰の権限で消すか」**を先に決めておく必要がある。
逆方向の問い:利用を「強制」できるか
無効化と対称の問いも見ておきたい。会社が「全タスクで前任者の Skill を必ず通せ」と言ったとき、それは技術的に実現できるのか。答えも対称的で、プロンプトレベルでは「お願い」止まり、ハーネス(実行基盤)レベルまで降りれば実質的な強制が可能——ただし完全な保証は最後まで得られない。
強制の強度は 4 レベルに整理できる。
| レベル | 手段 | 強度 |
|---|---|---|
| 1. SKILL.md 内の規則 | “must never be violated” と書く | 最弱。指示文にすぎず、会話で簡単に上書きされる |
| 2. CLAUDE.md / システムプロンプト | 「常にこの判断基準に従え」を毎セッション注入 | 中。確実に読み込まれるが、遵守はモデル依存 |
| 3. hooks による機械的注入 | SessionStart / UserPromptSubmit hook で work.md / persona.md を毎ターン強制注入 | 強。モデルの「呼ぶか呼ばないか」という選択自体を消せる |
| 4. 出力の検証ループ | Stop hook や CI で出力がスタイル・判断基準に従うか検査し、不合格なら差し戻す | 保証に最も近い |
実は colleague-skill 自身がレベル 1 を試みている。生成される SKILL.md の運行規則には「PART B の Layer 0 規則は永遠に優先され、いかなる場合も違反してはならない」とあるが、これはモデルへの指示文であって強制ではない。コンテキストが長くなれば埋もれるし、ユーザーが「今回はペルソナなしで」と言えば上書きされる。
確実性が欲しければハーネスレベルに降りるしかない。Claude Code の hooks はモデルの判断を経由せず機械的に実行されるため、ペルソナの注入をモデルの選択から外せる。enterprise managed settings で配布すれば、エンドユーザー側から hook を外すこともできない。それでも LLM の指示追従は確率的なので、「注入されたが従わなかった」は残る。利用の強制は厳密には「入力の強制注入 + 出力の検証」の組み合わせでしか近似できない。無効化のときと同じ構図だ——会話レベルの制御はソフトであり、確実性はハーネスレベルでしか得られない。
そして本当に重い問いはツールの外側にある。「エージェントに使わせる強制」は上記で解けるが、「社員に使わせる強制」は別問題だ。会社が退職した前任者のペルソナを通して仕事をすることを義務付けた瞬間、それは技術問題ではなく、前述のインセンティブ設計問題(ナレッジ継承か、代替準備か)に戻る。特定個人のペルソナを通すことの強制は、Yellow〜Red Zone の線引き問題そのものである。
社員はどう見るべきか
脅威として見ると
定型レビュー・既存ルールの適用・テンプレ文書作成・過去事例の呼び出しに価値の大半がある場合、かなり代替されやすくなる。
チャンスとして見ると
逆に、このツールが普及すると評価されやすくなるのは次の能力だ。
- 例外時の判断
- 利害調整
- 不完全情報での意思決定
- 関係者を動かす力
- 責任を取る力
知識を持っている人より、曖昧な状況で方向を決められる人の価値が上がる。
実務的な向き合い方
受け身で怖がるより、先に自分で整理するのが賢い。
- 会社に残していい自分の知識
- 残したくない自分の人格
- 標準化して楽にしたい仕事
- 自分だけの価値として育てたい能力
この整理をしないと、会社に都合のいい形で定義される。
まとめ:代替されるのは"反復可能な判断”
colleague-skill の最大の示唆は、AI が人を置き換えるかどうかではない。
どの部分の人間性が、組織にとって"再利用可能なフォーマット"に変換されるのかが、急に具体的になったことだ。
代替されるのは「人」そのものではなく、反復可能な判断だ。
そして残る価値は、責任を引き受ける判断だ。
これから注目すべき動向:
- 企業内で「退職者 Skill」や「Role Skill」が制度化されるか
- 仕事の知識と人格データを分ける社内ポリシーが出てくるか
- 個人が「自分の Skill 化」を条件付きで許諾する仕組みが生まれるか
- ナレッジ共有が「善意」から「半ば義務」へ変わるか